Topic 12
グループ別の記述統計:群ごと平均など
Grouped descriptive statistics with summary table and bar plot
比較分析の前に、各群の基本傾向をそろった形で確認するページです。群ごとの平均、SD、中央値、n を表にまとめ、棒グラフや生データ点で違いの見え方を整理します。
このページでは、Control、Program A、Program B の3群を例に、群ごとの score の平均とばらつきを整理します。ここでの目的は、検定で有意差を出すことではなく、比較の土台となる見取り図をつくることです。
このページのゴール
- group_by() と summarise() を使って群別の記述統計表を作れるようになる
- 平均、SD、中央値、n を群ごとに並べて読めるようになる
- 棒グラフと生データ点を組み合わせて、群差の見え方を説明できるようになる
- 検定結果と混同せずに、群別の記述統計を本文へ落とし込めるようになる
Start here
まず押さえる4つのポイント
1. 群別記述統計は「比較の前の地図」
いきなり検定に入る前に、各群の平均、SD、中央値、n をそろえて見ると、どこに差がありそうかを把握しやすくなります。
2. 平均だけでなく n と SD を並べる
平均が高い群でも、ばらつきが大きければ解釈は変わります。n と SD を並べることで、群の安定性が見えやすくなります。
3. 棒グラフだけに頼りすぎない
棒グラフは平均を見るのに便利ですが、個々の点が隠れやすい弱点があります。生データ点や箱ひげ図を補助的に使うと安心です。
4. ここでは「有意差」とは書かない
群別記述統計の段階で言えるのは、どの群が高そうか・ばらつきが大きそうかです。統計的有意差は検定結果があってはじめて書けます。
Basics
分析の概要と前提条件
何をまとめるのか
群別記述統計では、group というカテゴリごとに score の平均、SD、中央値、n をまとめます。比較研究の序盤で、どの群が高いか、ばらつきが大きいかを見取るのに役立ちます。
必要なデータ形式:1行が1観測で、group 列と score 列を持つ long / tidy 形式です。
向いている場面
- 検定前に各群の傾向を整理したいとき
- 報告書の「対象者の特徴」や「基礎集計」を作るとき
- 群の偏りや n のアンバランスを確認したいとき
別の方法を考える場面
- 群差を検定したいなら t 検定や ANOVA へ進みます
- カテゴリ変数の割合差を見たいならクロス集計や割合表が向いています
- 群内分布を詳しく見たいなら箱ひげ図やヒストグラムも併用します
最低限そろえたい項目
本文では平均と SD だけでも読めますが、表には n と中央値も入れておくと、後で見返したときに解釈しやすくなります。
- 群のラベルが正しく整理されていること
- 各群の n が極端に違わないか確認すること
- 平均の差をそのまま「有意差」と書かないこと
Checklist
集計前に確認したいこと
1. 群変数の水準を確認する
Control、Program A、Program B のようにラベルが揃っているかを見ます。表記ゆれがあると group_by() が別群として扱ってしまいます。
2. 各群の n をみる
極端に小さい群があると、平均や SD の安定性が落ちます。群ごとの n は最初に確認したい項目です。
3. 外れ値の有無をみる
平均は外れ値に引っ張られるので、群別の生データ点や箱ひげ図も補助的に確認すると安心です。
4. エラーバーの意味を書く
棒グラフにエラーバーを付けるなら、それが SD なのか SE なのか 95%CI なのかを明示します。
Data structure
データの形をつかむ
サンプルは Control、Program A、Program B の3群で、各群 12 名ずつです。score の群平均は Control < Program A < Program B の順でした。
サンプルデータの先頭
| id | group | score |
|---|---|---|
| 1 | Control | 62.6 |
| 2 | Control | 64.9 |
| 3 | Control | 61.9 |
| 4 | Control | 69.7 |
| 5 | Control | 63.3 |
| 6 | Control | 79.4 |
| 7 | Control | 60.7 |
| 8 | Control | 60.9 |
| 9 | Control | 58.8 |
群別記述統計表
| group | n | mean | sd | median | se |
|---|---|---|---|---|---|
| Control | 12 | 65.69 | 6.65 | 62.95 | 1.92 |
| Program A | 12 | 73.36 | 8.07 | 73.90 | 2.33 |
| Program B | 12 | 79.67 | 5.57 | 78.55 | 1.61 |
この段階では、Program B の平均が最も高く、Control が最も低いことが見て取れます。ただし、ここではまだ検定結果までは言いません。
R code
Rコードを順番に実行する
library(tidyverse)
dat <- read.csv("sample-data/sample_grouped_descriptive_scores.csv")
head(dat)
table(dat$group)group_table <- dat %>%
group_by(group) %>%
summarise(
n = n(),
mean = mean(score),
sd = sd(score),
median = median(score),
se = sd / sqrt(n)
)
group_tablelibrary(ggplot2)
ggplot(dat, aes(x = group, y = score)) +
stat_summary(fun = mean, geom = "col", width = 0.62, alpha = 0.8) +
stat_summary(fun.data = mean_se, geom = "errorbar", width = 0.14) +
geom_jitter(width = 0.07, alpha = 0.55, size = 2) +
labs(
x = NULL,
y = "Score",
title = "Grouped descriptive statistics"
) +
theme_minimal(base_size = 13)Output
出力のどこを読めばよいか
群別記述統計では、各群の n、平均、SD、中央値 を順番に確認し、棒グラフや生データ点と対応づけて読みます。
SD = 6.65
SD = 8.07
SD = 5.57
3 groups
この出力をどう解釈するか
平均値だけを見ると、Control は 65.69、Program A は 73.36、Program B は 79.67 で、Program B が最も高い傾向にあります。
ただし、SD も各群で異なるため、「どのくらい散らばっているか」を一緒に見ることが大切です。群別記述統計は、後で ANOVA や t 検定を読むときの土台になります。
Figure reading
棒グラフと生データ点をどう読むか
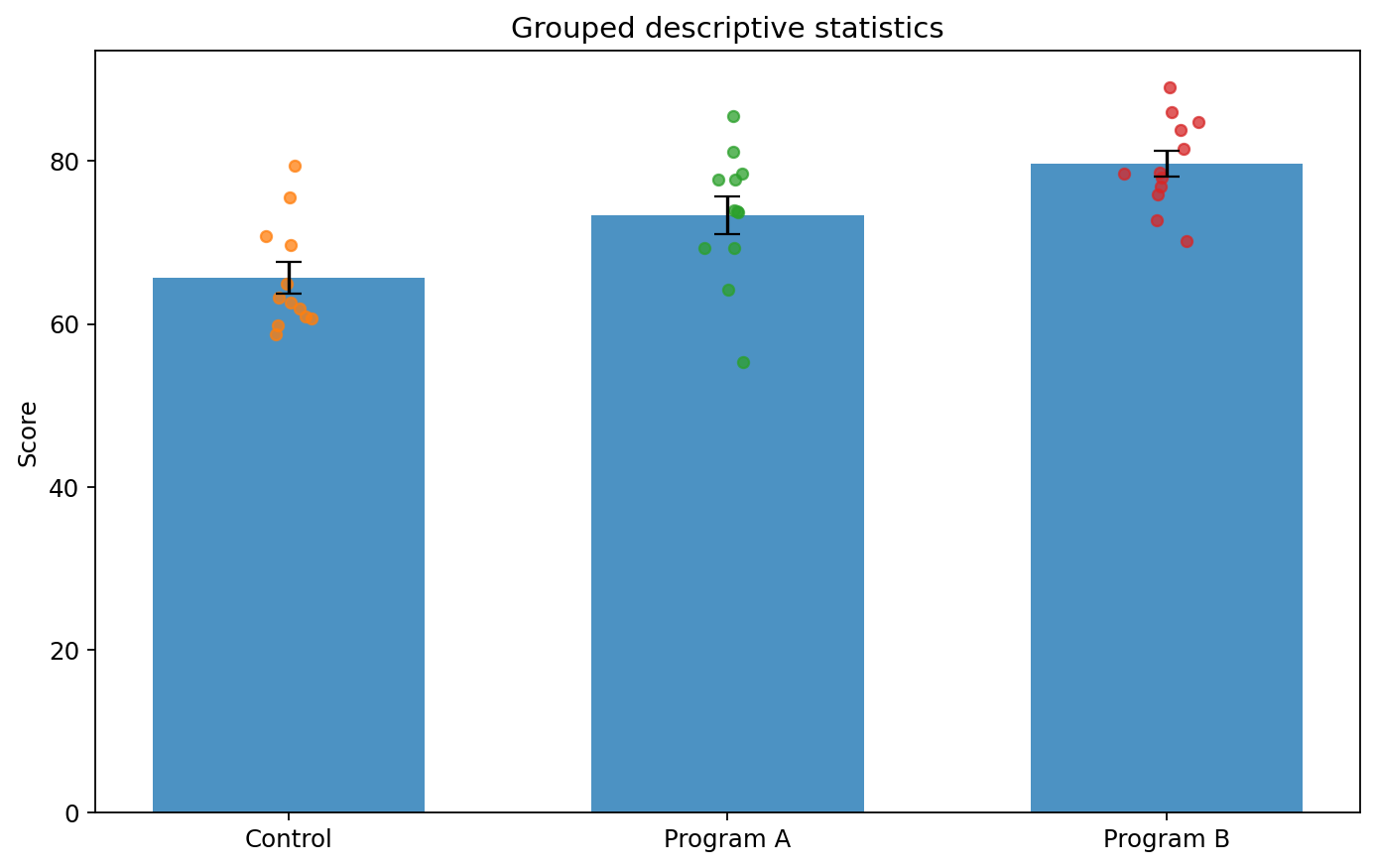
図1 群別平均、エラーバー、生データ点による score の比較
Figure 1. Group-wise means, error bars, and raw data points for score.
棒の高さ
棒の高さは平均を表します。Program B の棒が最も高く、Control が最も低いことが直感的に分かります。
エラーバーの意味
ここでは標準誤差を示しています。重なりの有無だけで有意差を判断するのではなく、あくまでばらつきの目安として使います。
生データ点の役割
個々の点を見ると、各群の散らばり具合や外れ値候補が把握しやすくなります。棒だけでは見えない情報です。
検定結果と分けて読む
図から差の方向は見えますが、統計的判断は別ページの ANOVA と組み合わせて行います。
Report writing
レポートや論文での書き方
Japanese
結果記述例(日本語)
群別の記述統計を表1に示した。score の平均は Control 群で 65.69(SD = 6.65)、Program A 群で 73.36(SD = 8.07)、Program B 群で 79.67(SD = 5.57)であり、Program B 群で最も高い傾向がみられた。
English
Report writing example
Table 1 presents the descriptive statistics by group. The mean score was 65.69 (SD = 6.65) in the Control group, 73.36 (SD = 8.07) in Program A, and 79.67 (SD = 5.57) in Program B, suggesting the highest average score in Program B.
Caption
図表キャプション例
表1 群別の記述統計
Figure 1. Group-wise means, error bars, and raw data points for score.
Common mistakes
よくあるミス
平均の差をそのまま「有意差」と書く
群別記述統計は見取り図です。差がありそうに見えても、検定なしに有意と表現しないようにします。
n を省略する
群の人数が違うと平均の安定性も変わるので、n を書かないと群比較の前提が見えなくなります。
棒グラフだけで済ませる
個々の点が見えないと、外れ値やばらつきの違いに気づきにくくなります。可能なら生データ点や箱ひげ図も併用します。
FAQ
初心者がひっかかりやすい質問
Q. 群が2つでも同じようにまとめますか?
A. はい。2群でも n、平均、SD、中央値をそろえてまとめると、t 検定へ進む前の整理がしやすくなります。
Q. エラーバーは SD と SE のどちらが良いですか?
A. 目的によります。群内の散らばりを見せたいなら SD、平均の不確実性を見せたいなら SE や 95%CI が使われます。
Q. 棒グラフと箱ひげ図のどちらが良いですか?
A. 平均に焦点を当てるなら棒グラフ、分布の形を見たいなら箱ひげ図が向いています。初学者には両方を比べる練習が役立ちます。
Q. 群ごとの中央値も必ず書くべきですか?
A. 本文では省略することもありますが、表には入れておくと後で分布の歪みを確認しやすくなります。
代替手法
代替手法・次のステップ
研究課題やデータ構造が少し変わると、選ぶべき手法も変わります。このテーマを土台にしつつ、どの条件で別の方法へ進むかを押さえておくと、分析計画が立てやすくなります。
一元配置 ANOVA
3群以上の平均差を統計的に検定したいときは、一元配置 ANOVA が自然な次の一歩です。
対応のない t 検定
群が2つなら、独立2群の t 検定へ進みます。群別記述統計はその前提整理として役立ちます。
グループごとの割合比較
目的変数が数値ではなくカテゴリなら、人数や割合の表・積み上げ棒グラフがより適切です。
参考資料
参考資料
このページの内容を深掘りしたいときに役立つ、公式ドキュメントと一次資料をまとめています。まずは関数の仕様、その次に補助的な可視化や読み方の資料を見ると理解しやすくなります。
運営と利用上の注意
このページの位置づけ
本サイトのトピックページは、Rによるデータ分析の学習支援とレポート作成の補助を目的としたオリジナル解説です。サンプルデータとコードは再現練習用に作成しているため、実データを扱う際には研究計画・前提条件・欠測・外れ値・尺度水準をあらためて確認してください。
編集方針
ページ本文は、標準的な統計手法、Rの公式ドキュメント、一次資料に近い参考文献を優先して整理しています。更新や訂正の方針は編集方針ページで公開しています。