Topic 11
記述統計のまとめ:平均・中央値・分散など
Descriptive statistics table with histogram and reporting examples
分析に入る前の出発点となるページです。数値変数の中心とばらつきを表で整理し、どの指標をどんな場面で使い分けるかを学びます。
このページでは、age・study_hours・score の3変数を例に、記述統計の作り方と読み方を整理します。サンプルは 30 人分で、平均だけでなく中央値や IQR も併記し、分布の偏りに応じて書き方を切り替える考え方まで扱います。
このページのゴール
- 平均 ± SD と中央値 (IQR) を状況に応じて使い分けられるようになる
- summary() や summarise(across()) を使って、複数変数の記述統計表を作れるようになる
- ヒストグラムを見て、中心・広がり・歪みの有無を文章化できるようになる
- レポートや論文で使える記述統計の書き方を日本語と英語で身につける
Start here
まず押さえる4つのポイント
1. 記述統計は分析の入口
どんな検定やモデルに進む前でも、まずデータの中心・広がり・範囲を確認します。ここを飛ばすと、後の解釈が不安定になりやすくなります。
2. 平均だけでなく中央値もみる
平均はよく使いますが、外れ値や歪みに影響を受けやすい指標です。中央値や IQR を並べると、分布の偏りに気づきやすくなります。
3. n と欠測も含めて書く
記述統計は数字だけではなく、何件をもとに計算したかも重要です。実務では欠測の有無も一緒に確認しておくと安心です。
4. 表と図を組み合わせる
表は正確な値を、図は分布の形を伝えるのに向いています。表だけ、図だけで終わらせない構成が実務では使いやすくなります。
Basics
分析の概要と前提条件
何をまとめるのか
記述統計では、各変数について中心(平均・中央値)、広がり(SD・IQR)、範囲(最小値・最大値)を整理します。数値を並べるだけでなく、「分布はどのくらい偏っているか」「外れた値がありそうか」を考える入口でもあります。
必要なデータ形式:1行が1観測で、age や score のような数値変数を含むデータです。カテゴリ変数は、別の表として人数や割合をまとめます。
よく使う指標
- 平均 ± SD:概ね対称な分布の要約
- 中央値 (IQR):歪みや外れ値に比較的強い要約
- 最小値・最大値:データ範囲の確認
気をつけたいこと
- 尺度水準が違う変数を同じ指標で雑に並べない
- 欠測があるときは有効 n を確認する
- 平均だけ書いて分布の偏りを隠さない
代表的な要約量
平均はデータ全体の重心、中央値は真ん中の位置、IQR は中央 50% の広がりを表します。どれを主役にするかは、分布の形によって変わります。
- 平均は外れ値の影響を受けやすい
- 中央値と IQR は歪みのある分布でも使いやすい
- 記述統計は検定結果の代わりではなく、出発点です
Checklist
集計前に確認したいこと
1. 数値変数かどうか
文字列やカテゴリ変数が混ざっていると、平均や SD が意味を持ちません。型を最初に確認します。
2. 欠測値があるか
欠測があると、変数ごとの n が変わります。必要に応じて na.rm = TRUE を使い、有効な件数も記録します。
3. 分布の偏りや外れ値
平均だけを見ると、極端な値に引っ張られることがあります。ヒストグラムや箱ひげ図を併用して確認します。
4. 何を本文に書くか
すべての統計量を本文に並べる必要はありません。本文では重要な変数に絞り、詳しい表は表として分けると読みやすくなります。
Data structure
データの形をつかむ
サンプルは 30 人分で、年齢、学習時間、テスト得点の3変数を使います。score の平均は 74.83 点、中央値は 77.5 点でした。
サンプルデータの先頭
| id | age | study_hours | score |
|---|---|---|---|
| 1 | 24.1 | 3.9 | 53.0 |
| 2 | 19.5 | 5.5 | 70.9 |
| 3 | 18.8 | 6.7 | 85.3 |
| 4 | 20.1 | 1.9 | 61.0 |
| 5 | 18.7 | 1.2 | 54.2 |
| 6 | 23.5 | 5.7 | 76.7 |
| 7 | 22.4 | 3.4 | 72.2 |
| 8 | 21.9 | 6.8 | 81.2 |
記述統計表の例
| 変数 | n | 平均 ± SD | 中央値 (IQR) | 最小〜最大 |
|---|---|---|---|---|
| age | 30 | 21.10 ± 1.60 | 21.4 (19.8–22.2) | 18.4 〜 24.1 |
| study_hours | 30 | 4.84 ± 1.68 | 4.8 (3.9–5.8) | 1.2 〜 8.9 |
| score | 30 | 74.83 ± 11.07 | 77.5 (68.0–83.2) | 51.9 〜 91.3 |
R code
Rコードを順番に実行する
library(tidyverse)
dat <- read.csv("sample-data/sample_descriptive_statistics.csv")
head(dat)
summary(dat)# 複数変数の記述統計表を作る例
dat %>%
summarise(
across(
c(age, study_hours, score),
list(
mean = mean,
sd = sd,
median = median,
q1 = ~quantile(.x, 0.25),
q3 = ~quantile(.x, 0.75),
min = min,
max = max
),
.names = "{.col}_{.fn}"
)
)
# score だけを詳しく見る
mean(dat$score)
sd(dat$score)
median(dat$score)
IQR(dat$score)library(ggplot2)
ggplot(dat, aes(x = score)) +
geom_histogram(bins = 8, color = "white") +
geom_vline(aes(xintercept = mean(score)), linetype = 2, linewidth = 1) +
geom_vline(aes(xintercept = median(score)), linetype = 3, linewidth = 1) +
labs(
x = "Score",
y = "Count",
title = "Distribution of score"
) +
theme_minimal(base_size = 13)Output
出力のどこを読めばよいか
記述統計では、まず n、平均、SD、中央値、IQR、最小値、最大値を確認し、必要に応じてヒストグラムの形と結びつけて読みます。
観測数
中心と広がり
頑健な要約量
最小値〜最大値
この出力をどう解釈するか
score の平均は 74.83、SD は 11.07 でした。中央値は 77.5 で、平均と大きく離れていないため、score の分布は極端に歪んでいないと読みやすい例です。
ただし、本文では必ずしも全指標をすべて書く必要はありません。たとえば本文では score の平均 ± SD を書き、詳しい表では age や study_hours も含めた一覧を示す、という分け方が使いやすくなります。
Figure reading
ヒストグラムをどう読むか
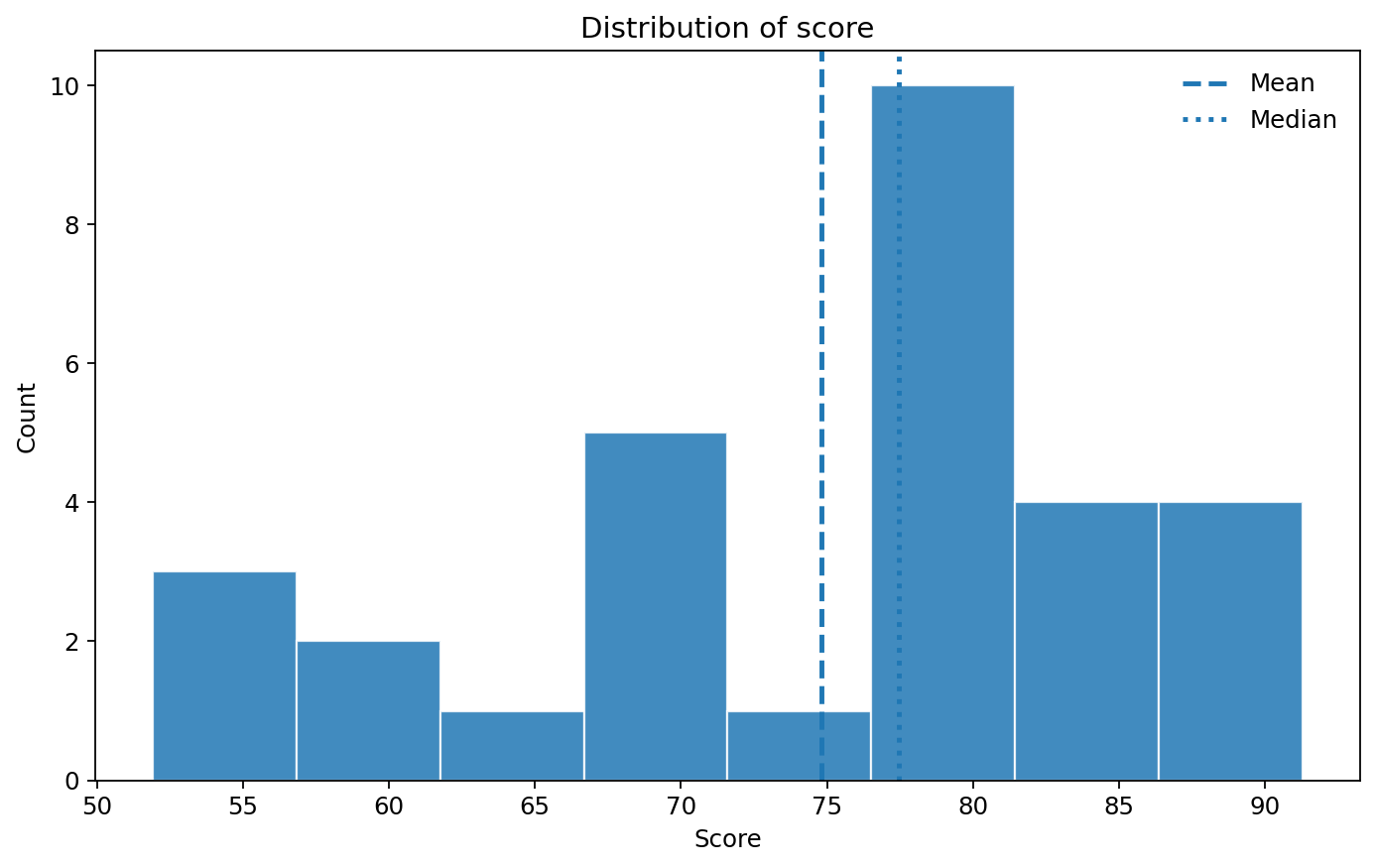
図1 テスト得点の分布を示すヒストグラム
Figure 1. Histogram of test scores.
分布の中心
平均線と中央値線が近ければ、大きな歪みは強くなさそうだと考えやすくなります。
広がりの大きさ
左右に広く散っていれば SD も大きくなります。ヒストグラムは SD の数値を視覚的に補います。
歪みの有無
右裾や左裾が長いときは、平均より中央値の方が代表値としてしっくりくる場合があります。
離れた値の有無
極端に離れた値が見えたら、外れ値のページへ進んで詳しく確認します。
Report writing
レポートや論文での書き方
Japanese
結果記述例(日本語)
対象者 30 名のテスト得点の平均は 74.83 点(SD = 11.07)で、中央値は 77.5 点(IQR = 15.2)であった。図1に得点分布のヒストグラムを、表1に主要変数の記述統計を示した。
English
Report writing example
The mean test score among the 30 participants was 74.83 (SD = 11.07), and the median was 77.5 (IQR = 15.2). Figure 1 shows the distribution of scores, and Table 1 summarizes the descriptive statistics of the main variables.
Caption
図表キャプション例
表1 主要変数の記述統計
Figure 1. Histogram of test scores.
Common mistakes
よくあるミス
平均だけで済ませてしまう
平均は便利ですが、偏った分布や外れ値に弱い指標です。中央値や IQR も併記すると、データの姿が伝わりやすくなります。
n を書かない
どのくらいのサンプルから計算した数字なのかがないと、解釈の前提が抜け落ちます。記述統計表では n を習慣的に入れます。
図と表を分断してしまう
表に数字、図に分布の形があるので、両者を往復しながら解釈する方が理解しやすくなります。
FAQ
初心者がひっかかりやすい質問
Q. いつ平均ではなく中央値を書くべきですか?
A. 分布が歪んでいるときや外れ値の影響が大きいときは、中央値と IQR の方が安定した要約になります。
Q. 分散も必ず書くべきですか?
A. 分散より SD の方が本文では直感的に読みやすいことが多いです。必要に応じて表に入れる形で十分です。
Q. カテゴリ変数の記述統計はどうしますか?
A. 平均ではなく、人数と割合でまとめます。カテゴリ変数は別表として扱うと整理しやすくなります。
Q. 記述統計だけで結論を書いてよいですか?
A. 記述統計は出発点です。差や関連について結論を出したいときは、目的に応じた検定やモデルへ進みます。
代替手法
代替手法・次のステップ
研究課題やデータ構造が少し変わると、選ぶべき手法も変わります。このテーマを土台にしつつ、どの条件で別の方法へ進むかを押さえておくと、分析計画が立てやすくなります。
グループ別記述統計
群ごとの平均や SD を並べたいときは、group_by() を使った群別集計が自然な次の一歩です。
外れ値の検出
ヒストグラムや箱ひげ図で極端な値が気になったら、IQR ルールや箱ひげ図で詳しく確認します。
正規性の確認
t 検定や回帰へ進む前に、分布形状や QQ プロットをもう一歩詳しく見たいときに役立ちます。
参考資料
参考資料
このページの内容を深掘りしたいときに役立つ、公式ドキュメントと一次資料をまとめています。まずは関数の仕様、その次に補助的な可視化や読み方の資料を見ると理解しやすくなります。
運営と利用上の注意
このページの位置づけ
本サイトのトピックページは、Rによるデータ分析の学習支援とレポート作成の補助を目的としたオリジナル解説です。サンプルデータとコードは再現練習用に作成しているため、実データを扱う際には研究計画・前提条件・欠測・外れ値・尺度水準をあらためて確認してください。
編集方針
ページ本文は、標準的な統計手法、Rの公式ドキュメント、一次資料に近い参考文献を優先して整理しています。更新や訂正の方針は編集方針ページで公開しています。