Topic 13
外れ値の検出と可視化:箱ひげ図+スウォーム
Outlier detection with IQR rule, boxplot, and point display
極端な値をどう見つけ、どう扱うかを学ぶページです。箱ひげ図で候補を見つけ、IQR ルールで整理し、除外・保持・感度分析の考え方までつなげます。
このページでは、score の分布のなかから外れ値候補を見つける手順を扱います。サンプルでは 2 件が IQR ルールのフェンス外にありましたが、ここで大事なのは『外れ値 = 自動削除』ではないという点です。
このページのゴール
- 箱ひげ図と IQR ルールを使って外れ値候補を特定できるようになる
- 外れ値候補と入力ミス・測定ミス・妥当な極端値を区別する視点を持てるようになる
- 外れ値をどう扱ったかを、分析ノートや本文で透明に説明できるようになる
- 外れ値の確認を、記述統計や後続の検定へ自然につなげられるようになる
Start here
まず押さえる4つのポイント
1. 外れ値候補は「発見」であって「削除命令」ではない
箱ひげ図や IQR ルールで見つかるのは、あくまで外れ値候補です。まずはデータ入力ミスか、妥当な極端値かを確認します。
2. 箱ひげ図は第一歩として便利
中央値、四分位範囲、ひげ、外れた点を一度に見られるので、初学者が外れ値を確認する入り口として使いやすい図です。
3. IQR ルールを機械的に覚える
Q1 − 1.5×IQR より小さい、または Q3 + 1.5×IQR より大きい値を、ひとまず候補として拾います。
4. 扱い方を記録に残す
除外したのか、そのまま使ったのか、感度分析をしたのかを分析ノートや本文に残すと、再現性と透明性が上がります。
Basics
分析の概要と前提条件
何を見ているのか
外れ値の検出では、分布全体から大きく離れた観測値があるかを確認します。平均、SD、回帰係数、p 値は少数の極端値で動くことがあるため、前処理や結果解釈の前に一度チェックしておくと安心です。
必要なデータ形式:1行が1観測で、score のような数値変数を持つ形です。
外れ値候補の原因
- 入力ミス・測定ミス
- 単位の混在や転記ミス
- 本当に起きた稀な観測値
対応の考え方
- 明らかな誤りなら修正・除外を検討する
- 妥当な極端値なら保持し、その影響を確認する
- 平均だけでなく中央値やロバスト法も考える
IQR ルール
今回のサンプルでは Q1 = {out['q1']:.2f}, Q3 = {out['q3']:.2f}, IQR = {out['iqr']:.2f} でした。したがって、{out['lf']:.2f} 未満または {out['uf']:.2f} 超の値が外れ値候補になります。
- IQR ルールはあくまで候補抽出のルールです
- データの文脈を無視して自動削除しないこと
- 平均が引っ張られていないかを確認すること
Checklist
外れ値を見つけたあとに確認したいこと
1. 入力ミスではないか
まずは元データや計測記録を見て、桁間違い、単位違い、転記ミスがないかを確認します。
2. 実際にあり得る値か
極端でも、現実にあり得る観測値なら、そのまま保持する選択もあります。文脈判断が重要です。
3. 結果がどれだけ変わるか
保持した場合と除いた場合で、平均や回帰係数が大きく変わるかを比較すると、影響の大きさが分かります。
4. 処理内容を文章化する
「IQR ルールで外れ値候補を確認したが、入力ミスではなかったため保持した」のように、判断の痕跡を残します。
Data structure
データの形をつかむ
サンプルは 28 件の score データです。IQR ルールでは 2 件がフェンス外にあり、候補として抽出されました。
サンプルデータの先頭
| id | score |
|---|---|
| 1 | 71.9 |
| 2 | 83.1 |
| 3 | 65.8 |
| 4 | 70.9 |
| 5 | 62.6 |
| 6 | 64.3 |
| 7 | 65.9 |
| 8 | 70.2 |
| 9 | 77.6 |
| 10 | 71.4 |
IQR ルールの要約
| 指標 | 値 |
|---|---|
| Q1 | 69.07 |
| Q3 | 77.38 |
| IQR | 8.30 |
| Lower fence | 56.62 |
| Upper fence | 89.83 |
| Flagged points | 2 |
フェンス外に出た観測値は「怪しい」と分かった段階です。ここから先は、元データの確認と文脈判断が必要です。
| id | score |
|---|---|
| 27 | 43.6 |
| 28 | 101.7 |
R code
Rコードを順番に実行する
library(tidyverse)
dat <- read.csv("sample-data/sample_outlier_scores.csv")
head(dat)
summary(dat$score)q1 <- quantile(dat$score, 0.25)
q3 <- quantile(dat$score, 0.75)
iqr_value <- IQR(dat$score)
lower_fence <- q1 - 1.5 * iqr_value
upper_fence <- q3 + 1.5 * iqr_value
outliers <- dat %>%
filter(score < lower_fence | score > upper_fence)
outliers
# base R の簡易チェック
boxplot.stats(dat$score)$outlibrary(ggplot2)
ggplot(dat, aes(x = "", y = score)) +
geom_boxplot(width = 0.28, outlier.shape = NA) +
geom_jitter(width = 0.06, height = 0, alpha = 0.75, size = 2) +
labs(
x = NULL,
y = "Score",
title = "Potential outliers based on the IQR rule"
) +
theme_minimal(base_size = 13)Output
出力のどこを読めばよいか
外れ値の確認では、Q1、Q3、IQR、上下フェンス、そして候補として拾われた観測値の ID を確認します。
第1四分位
第3四分位
中央50%の幅
IQR rule
この出力をどう解釈するか
今回のデータでは、下側フェンスは 56.62、上側フェンスは 89.83 でした。この範囲を外れる値として、ID 27, 28 が抽出されました。
ただし、この段階で「削除すべき」と決めるのではなく、入力ミスかどうか、研究上あり得る値かどうか、結果がどの程度変わるかを順に確認します。
Figure reading
箱ひげ図と点をどう読むか
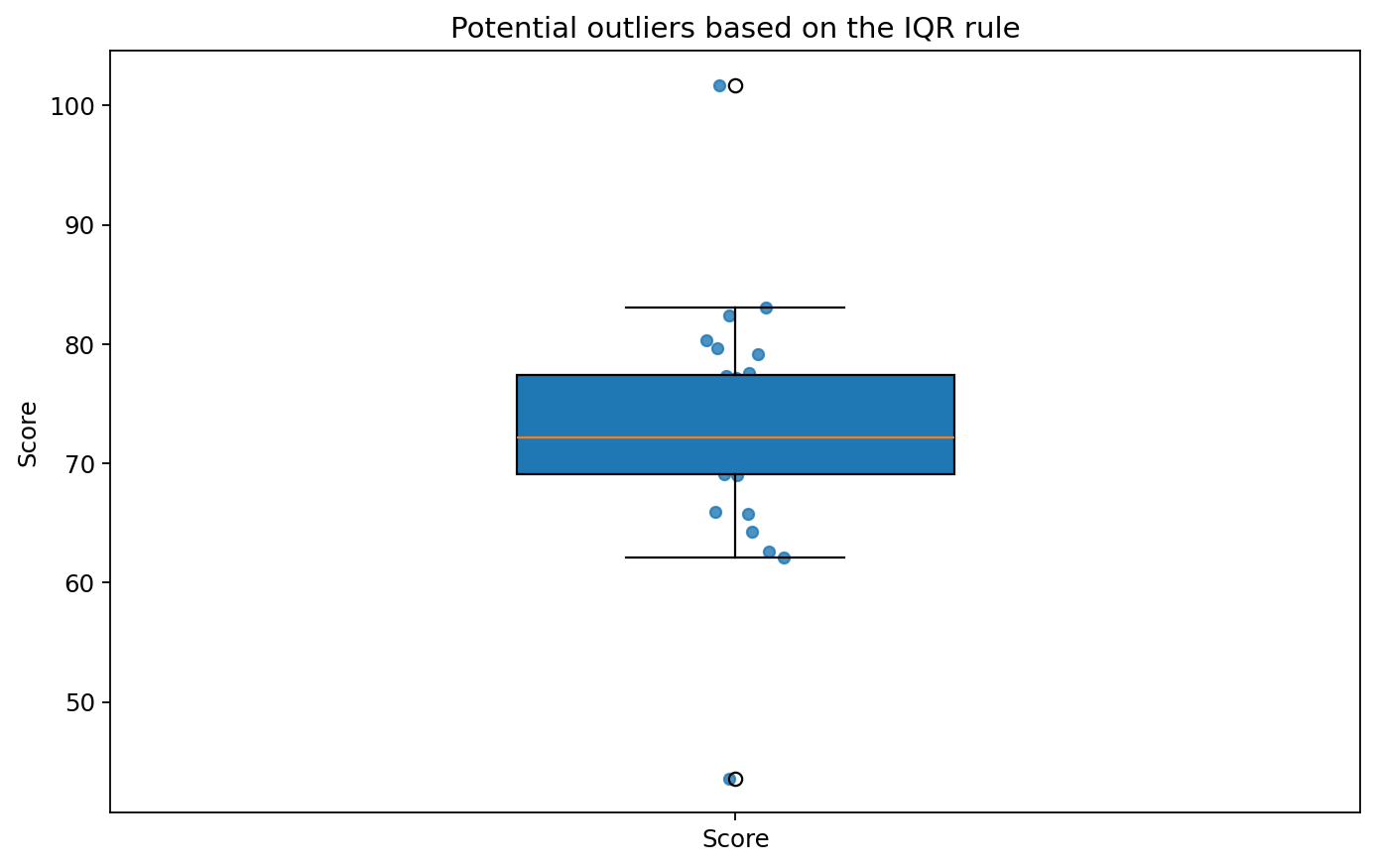
図1 箱ひげ図と観測値による外れ値候補の可視化
Figure 1. Visualization of potential outliers using a boxplot and raw data points.
箱の中央線
中央線は中央値です。平均とは違い、極端な値の影響を受けにくい指標です。
箱の外の点
ひげの外にある点は、IQR ルールで外れ値候補として扱われます。まずは候補としてメモします。
1点ずつ見える利点
点を重ねると、候補が何件あるか、どちら側に偏っているかが分かりやすくなります。
分布全体との関係
外れ値候補だけでなく、中心の集まりがどのあたりにあるかも同時に見えるので、全体解釈に役立ちます。
Report writing
レポートや論文での書き方
Japanese
結果記述例(日本語)
score の分布を箱ひげ図で確認したところ、IQR ルールに基づく外れ値候補が 2 件認められた(図1)。元データを確認した結果、いずれも入力ミスではなかったため、本解析では保持した。必要に応じて、外れ値を除いた感度分析もあわせて実施した。
English
Report writing example
Inspection of the boxplot identified two potential outliers according to the IQR rule (Figure 1). After checking the original records, these values were not considered data-entry errors and were therefore retained in the main analysis. A sensitivity analysis excluding these observations may also be reported when appropriate.
Caption
図表キャプション例
図1 箱ひげ図と観測値による外れ値候補の可視化
Figure 1. Visualization of potential outliers using a boxplot and raw data points.
Common mistakes
よくあるミス
見つけたらすぐ消してしまう
外れ値候補を自動削除すると、本当に意味のある極端値まで消してしまうことがあります。まずは文脈を確認します。
処理内容を記録しない
あとで再現できなくなるので、「どのルールで候補を見つけ、どう判断したか」を必ず残します。
平均だけ見て判断する
外れ値は平均を大きく動かすことがあります。中央値や図もあわせて見ると、より落ち着いて判断できます。
FAQ
初心者がひっかかりやすい質問
Q. IQR ルールにかかったら必ず外れ値ですか?
A. いいえ。あくまで候補です。観測文脈や記録確認をしたうえで判断します。
Q. z スコアで見てもよいですか?
A. はい。標準化した値で見る方法もありますが、初学者には箱ひげ図と IQR ルールの方が直感的で扱いやすいです。
Q. 外れ値があると t 検定は使えませんか?
A. 程度によります。外れ値の影響が大きそうなら、図の確認や感度分析、場合によっては別手法の検討が必要です。
Q. 箱ひげ図の点が1つもなければ安心ですか?
A. 大きな問題が見えにくいという意味では安心材料ですが、文脈上の異常値がないとは限りません。元データ確認は依然として重要です。
代替手法
代替手法・次のステップ
研究課題やデータ構造が少し変わると、選ぶべき手法も変わります。このテーマを土台にしつつ、どの条件で別の方法へ進むかを押さえておくと、分析計画が立てやすくなります。
中央値中心の要約
外れ値の影響が大きいときは、平均より中央値と IQR を主役にした報告の方が安定します。
感度分析
候補を保持した場合と除いた場合で結果がどう変わるかを比べると、影響の大きさを説明しやすくなります。
ロバスト手法
外れ値の影響を受けにくい統計量やモデルを使う方法もあります。まずは候補の存在を把握したうえで選びます。
参考資料
参考資料
このページの内容を深掘りしたいときに役立つ、公式ドキュメントと一次資料をまとめています。まずは関数の仕様、その次に補助的な可視化や読み方の資料を見ると理解しやすくなります。
運営と利用上の注意
このページの位置づけ
本サイトのトピックページは、Rによるデータ分析の学習支援とレポート作成の補助を目的としたオリジナル解説です。サンプルデータとコードは再現練習用に作成しているため、実データを扱う際には研究計画・前提条件・欠測・外れ値・尺度水準をあらためて確認してください。
編集方針
ページ本文は、標準的な統計手法、Rの公式ドキュメント、一次資料に近い参考文献を優先して整理しています。更新や訂正の方針は編集方針ページで公開しています。