Topic 6
単回帰分析:1説明変数 × 回帰直線
Simple linear regression with scatter plot and coefficient interpretation
1つの説明変数から1つの連続アウトカムを予測するときの基本テーマです。散布図で関係の形を確認し、lm() の出力から傾き・切片・R²・p値を読む流れを学びます。
このページでは、学習時間とテスト得点のように、1つの数値変数から別の数値変数を説明したいときに使う単回帰分析を扱います。サンプルデータでは 28 人分のデータを用い、study_hours が 1 時間増えると score が平均してどのくらい変わるかを R で確かめます。
このページのゴール
- 回帰式 y = β0 + β1x の意味を、切片と傾きのレベルで説明できるようになる
- 散布図・回帰直線・95%信頼帯を合わせて読み、関係の向きと強さを確認できるようになる
- lm() の出力から傾き、95%CI、R²、p値を拾って要約できるようになる
- 関連があることと因果であることを区別しながら、日英の結果記述に落とし込めるようになる
Start here
まず押さえる4つのポイント
1. 単回帰は「傾き」を読む分析
単回帰分析では、説明変数が1単位増えたときに目的変数が平均してどれだけ変わるかを傾き β1 で表します。今回なら、study_hours が1時間増えると score が何点変わるかを見ます。
2. まず散布図で形を確認する
回帰分析に入る前に、散布図で右上がり・右下がり・曲がり・外れ値の有無を見ます。回帰式は便利ですが、図を見ずに係数だけ読むと関係の形を見落としやすくなります。
3. p値だけでなく R² も確認する
この例では傾きの p 値に加えて、R² = 0.817 を確認できます。R² は score のばらつきのうち、study_hours で説明できる割合の目安として使えます。
4. 回帰は因果を自動で証明しない
単回帰で分かるのは、まず変数どうしの関連の大きさと向きです。学習時間が増えるほど得点が高い関連が見えても、それだけで因果と断言することはできません。
Basics
分析の概要と前提条件
どんなときに使うか
単回帰分析は、1つの説明変数で1つの連続アウトカムを説明したいときの基本手法です。例として、学習時間と得点、年齢と血圧、広告費と売上などが挙げられます。
必要なデータ形式:1行が1観測で、study_hours のような説明変数と、score のような連続アウトカムを持つ形です。
向いている場面
- 説明変数が1つで、関係の方向と大きさをまず掴みたいとき
- 散布図でみると、おおむね直線で近似できそうなとき
- 予測式をシンプルに説明したいとき
別の方法を考える場面
- 説明変数が複数あるなら重回帰分析が候補です
- 目的変数が0/1ならロジスティック回帰を使います
- 散布図で明らかな曲線関係が見えるなら、変換や非線形項も検討します
回帰式はどう読むか
β0 は切片、β1 は傾きです。今回の推定では、傾きは 4.02 なので、study_hours が1時間増えるごとに score が平均して約 4.02 点高くなる関係が推定されます。
- 説明変数とアウトカムの関係が概ね直線的であること
- 残差のばらつきが極端に広がったり縮んだりしないこと
- 極端な外れ値が傾きを不自然に引っ張っていないこと
- 観測どうしが独立していること
Assumption check
前提条件はどう確認するか
単回帰分析では、散布図 → 残差プロット → 外れ値の確認の順で眺めると、初心者でも迷いにくくなります。
1. 散布図で線形性をみる
点が右上がりまたは右下がりに並んでいて、極端に曲がっていなければ、まずは単回帰で扱いやすい関係です。
2. 残差 vs 予測値で等分散性をみる
残差が扇形に広がると、ばらつきが説明変数に応じて変わっている可能性があります。まずは plot(mod, which = 1) で形を見ます。
3. Q-Q プロットで残差の形をみる
単回帰で意識したいのは目的変数そのものより、残差の分布です。厳密さよりも、大きく外れていないかを把握する姿勢が大切です。
4. 影響の大きい点に注意する
少数の極端な点があると、傾きが大きく変わることがあります。散布図で浮いた点がないか、Cook 距離や残差を補助的に確認すると安心です。
Data structure
データの形をつかむ
ここでは、28 人の学習時間とテスト得点を使います。学習時間は 1.3 〜 9.7 時間の範囲にあり、score の平均は 71.8 点です。
サンプルデータの先頭
| id | study_hours | score |
|---|---|---|
| 1 | 1.7 | 57.2 |
| 2 | 1.3 | 55.5 |
| 3 | 2.5 | 71.9 |
| 4 | 2.9 | 57.1 |
| 5 | 1.7 | 51.2 |
| 6 | 2.3 | 51.8 |
| 7 | 3.3 | 65.5 |
| 8 | 3.4 | 69.3 |
回帰係数の要約
| 指標 | 値 | 95%CI |
|---|---|---|
| 切片 β0 | 49.77 | 45.16 〜 54.38 |
| 傾き β1 | 4.02 | 3.25 〜 4.78 |
| 決定係数 R² | 0.817 | — |
| F 値 | 116.39 | df = 1, 26 |
この時点で、study_hours と score の間には右上がりの関係がありそうだと予想できます。実際に lm() を当てると、傾きは約 4.02 点/時間でした。
R code
Rコードを順番に実行する
library(tidyverse)
dat <- read.csv("sample-data/sample_simple_regression_scores.csv")
# まずは変数の範囲を確認
dat %>%
summarise(
n = n(),
min_hours = min(study_hours),
max_hours = max(study_hours),
mean_score = mean(score),
sd_score = sd(score)
)
head(dat)mod <- lm(score ~ study_hours, data = dat)
summary(mod)
confint(mod)
# 予測式の係数を取り出す
coef(mod)
# 予測値と残差を確認
dat$pred <- fitted(mod)
dat$resid <- resid(mod)library(ggplot2)
ggplot(dat, aes(x = study_hours, y = score)) +
geom_point(size = 2.6, alpha = 0.85) +
geom_smooth(method = "lm", se = TRUE, linewidth = 1.1) +
labs(
x = "Study hours",
y = "Score",
title = "Relationship between study hours and score"
) +
theme_minimal(base_size = 13)
# 残差診断の基本
par(mfrow = c(1, 2))
plot(mod, which = 1) # residuals vs fitted
plot(mod, which = 2) # normal Q-QOutput
出力のどこを読めばよいか
単回帰では、傾き β1、95%信頼区間、t 値と p 値、R²の順に確認すると整理しやすくなります。
切片 β0
1時間あたりの増加量
p < 0.001
説明率の目安
この出力をどう解釈するか
このサンプルでは、study_hours の傾きは 4.02(95%CI 3.25 〜 4.78)で、t(26) = 10.79, p < 0.001 でした。したがって、学習時間が長いほど得点が高いという正の関連が示唆されます。
R² は 0.817 で、score のばらつきの約 81.7% を study_hours だけで説明できる計算になります。p 値だけではなく、1時間増えると平均して何点変わるかを文章で書けると、結果が実務で使いやすくなります。
Figure reading
散布図と回帰直線をどう読むか
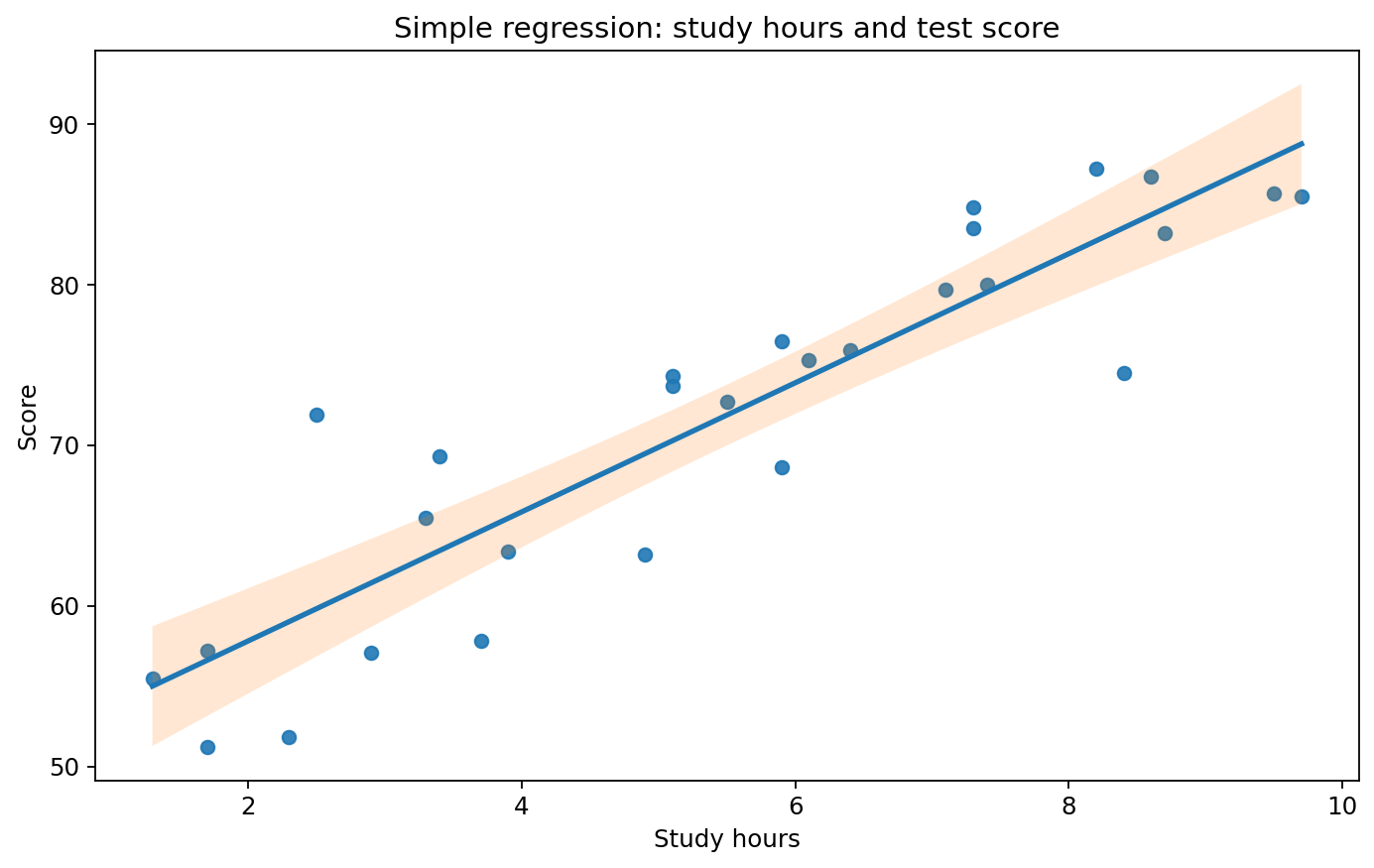
図1 学習時間とテスト得点の散布図および回帰直線
Figure 1. Scatter plot of study hours and test scores with the fitted regression line.
右上がりかどうか
点が全体として右上がりに並び、学習時間が長いほど得点が高くなる傾向が見て取れます。
回帰直線の傾き
直線の傾きが大きいほど、学習時間の違いが得点差として大きく現れます。今回の傾きは約4点/時間です。
信頼帯の幅
回帰直線の周りの帯は平均予測の95%信頼帯です。中央付近より端の方で広がりやすい点も確認しておきます。
外れた点の有無
直線から大きく離れた点があると、傾きや切片が影響を受けます。まずは図で存在を把握してから、必要なら残差も見ます。
Report writing
レポートや論文での書き方
Japanese
結果記述例(日本語)
単回帰分析の結果、学習時間はテスト得点と有意な正の関連を示した(β = 4.02, 95%CI 3.25–4.78, t(26) = 10.79, p < 0.001, R² = 0.817)。図1に学習時間と得点の散布図および回帰直線を示した。学習時間が長い参加者ほど、得点が高い傾向が観察された。
English
Report writing example
A simple linear regression showed that study hours were positively associated with test scores (β = 4.02, 95% CI 3.25 to 4.78, t(26) = 10.79, p < 0.001, R² = 0.817). Figure 1 presents the scatter plot and fitted regression line, indicating that students with longer study hours tended to obtain higher scores.
Caption
図表キャプション例
図1 学習時間とテスト得点の散布図および回帰直線
Figure 1. Scatter plot of study hours and test scores with the fitted regression line.
Common mistakes
よくあるミス
関連をすぐ因果だと書いてしまう
単回帰が示すのは、まず変数どうしの関連です。介入研究や実験設計が伴っていない限り、原因と結果を断定する書き方は避けます。
傾きの単位を書かない
「β = 4.02」だけでは、1時間増えるごとに4.02点上がるのか、別の尺度なのかが伝わりません。説明変数1単位あたりの変化量として書くと明快です。
観測範囲外へ外挿してしまう
このデータは 1.3〜9.7 時間の範囲で観測されています。たとえば 15 時間勉強したときの得点をこの式だけで予測するのは慎重であるべきです。
FAQ
初心者がひっかかりやすい質問
Q. 相関分析と何が違うのですか?
A. 相関分析は関連の強さを r で要約し、単回帰は「x が1単位増えると y がどれだけ変わるか」を傾きで表します。散布図は共通でも、出てくる量の意味が少し違います。
Q. 説明変数がカテゴリでも単回帰は使えますか?
A. 2値のカテゴリを 0/1 にして入れることはできます。その場合、傾きは2群の平均差に近い意味になります。
Q. R² が高ければ良いモデルですか?
A. 高いほど説明率は大きいですが、研究目的やデータの性質によって評価は変わります。残差の形や外れ値、目的に合った変数選択もあわせて見ます。
Q. p 値が有意でなくても図は載せるべきですか?
A. はい。散布図は、関係の向きやばらつき、外れ値の有無を伝えるので、結果解釈を支えてくれます。
代替手法
代替手法・次のステップ
研究課題やデータ構造が少し変わると、選ぶべき手法も変わります。このテーマを土台にしつつ、どの条件で別の方法へ進むかを押さえておくと、分析計画が立てやすくなります。
ピアソンの相関
まずは関連の強さだけを相関係数で要約したいときは、cor.test() による相関分析が分かりやすい入口になります。
重回帰分析
年齢や事前成績など、別の説明変数も同時に調整したいなら重回帰分析へ進みます。
非線形モデル
散布図が曲線的なら、多項式項やスプライン、対数変換などを検討します。まずは図で形を確認してから選びます。
参考資料
参考資料
このページの内容を深掘りしたいときに役立つ、公式ドキュメントと一次資料をまとめています。まずは関数の仕様、その次に補助的な可視化や読み方の資料を見ると理解しやすくなります。
運営と利用上の注意
このページの位置づけ
本サイトのトピックページは、Rによるデータ分析の学習支援とレポート作成の補助を目的としたオリジナル解説です。サンプルデータとコードは再現練習用に作成しているため、実データを扱う際には研究計画・前提条件・欠測・外れ値・尺度水準をあらためて確認してください。
編集方針
ページ本文は、標準的な統計手法、Rの公式ドキュメント、一次資料に近い参考文献を優先して整理しています。更新や訂正の方針は編集方針ページで公開しています。