Topic 7
重回帰分析:複数説明変数 × 回帰係数表
Multiple linear regression with coefficient table and adjusted interpretation
複数の説明変数を同時に入れて、各変数の『他の変数で調整したうえでの関連』を読みたいときの基本テーマです。単回帰より一歩進んで、交絡を意識した説明へ進みます。
このページでは、学習時間・出席率・事前テスト得点の3変数から期末得点を説明する重回帰分析を扱います。サンプルデータでは 42 人分のデータを用い、どの説明変数が final_score と独立に関連しているかを R で確かめます。
このページのゴール
- 重回帰の係数が『他の変数で調整した条件つきの関連』であると説明できるようになる
- lm() と summary() から係数、95%CI、F 検定、調整済み R² を拾えるようになる
- 係数表や係数プロットを使って、どの変数がどの向きに関連しているかを整理できるようになる
- 多重共線性や残差診断を、初心者向けの粒度で確認できるようになる
Start here
まず押さえる4つのポイント
1. 重回帰は「調整して読む」分析
重回帰では、他の説明変数を一定とみなしたうえで、ある変数が目的変数とどう関連するかを係数で表します。単回帰より一歩進んで、交絡を意識した読み方になります。
2. 係数の符号と単位を確認する
正の係数なら、その変数が大きいほど目的変数も高い方向です。ただし、1時間、1%、1点のように単位が違うので、数字だけ並べて単純比較しないよう注意します。
3. まず全体のモデルも見る
各係数の p 値だけでなく、F 検定や 調整済み R² を見て、モデル全体としてどのくらい説明できているかを確認します。
4. 残差と多重共線性にも目を向ける
重回帰では、残差の形に加えて、説明変数どうしが強く似すぎていないかも大切です。まずは相関行列や VIF を補助的に確認します。
Basics
分析の概要と前提条件
どんなときに使うか
重回帰分析は、1つの連続アウトカムに対して、2つ以上の説明変数を同時に入れたいときの基本手法です。今回なら、学習時間・出席率・事前テスト得点を同時に入れて期末得点を説明します。
必要なデータ形式:1行が1観測で、目的変数 final_score と、複数の説明変数が列として並ぶ形です。
向いている場面
- 複数の要因を同時に扱い、独立した関連を見たいとき
- 単回帰では交絡しそうな変数を調整したいとき
- 予測モデルの基本形を作りたいとき
別の方法を考える場面
- 目的変数が0/1ならロジスティック回帰を使います
- 説明変数が1つだけなら単回帰で十分です
- 強い非線形や交互作用がありそうなら、項の追加や別モデルも検討します
回帰式はどう読むか
たとえば β1 が学習時間の係数なら、出席率と事前得点が同じ条件で、学習時間が1時間長いと期末得点が平均してどれだけ高いかを表します。
- 目的変数と各説明変数の関係が大きく曲がっていないこと
- 残差のばらつきが極端に広がらないこと
- 観測どうしが独立していること
- 説明変数どうしが強く重なりすぎていないこと(多重共線性)
Assumption check
前提条件はどう確認するか
重回帰では、説明変数どうしの関係 → 残差プロット → 影響の大きい点の順で見ると整理しやすくなります。
1. 説明変数どうしが似すぎていないか
今回のサンプルでは、説明変数間の VIF は 1.17 以下で、極端な多重共線性は強く示唆されません。まずは相関行列や VIF を補助的に確認します。
2. 残差 vs 予測値で等分散性をみる
残差が扇形に広がると、ばらつきが予測値に応じて変わっている可能性があります。plot(mod, which = 1) を最初の診断図として見ます。
3. Q-Q プロットで残差の形をみる
重回帰でも意識したいのは、目的変数そのものより 残差の分布 です。大きく歪んでいないか、直線から強く外れていないかを確認します。
4. 影響の大きい観測に注意する
少数の観測が係数を強く動かすことがあります。Cook 距離やレバレッジを補助的に確認し、値の整合性も見直します。
Data structure
データの形をつかむ
ここでは、42 人の期末得点データを使います。final_score の平均は 71.1 点で、説明変数は学習時間・出席率・事前テスト得点の3つです。
サンプルデータの先頭
| id | study_hours | attendance_rate | prior_score | final_score |
|---|---|---|---|---|
| 1 | 5.6 | 86.4 | 70.3 | 82.0 |
| 2 | 5.3 | 72.2 | 66.6 | 64.1 |
| 3 | 4.0 | 94.3 | 54.6 | 64.0 |
| 4 | 1.7 | 75.9 | 76.7 | 73.7 |
| 5 | 7.5 | 78.2 | 68.3 | 72.1 |
| 6 | 4.6 | 73.6 | 82.0 | 76.6 |
| 7 | 5.1 | 73.8 | 78.8 | 69.7 |
| 8 | 3.9 | 80.6 | 66.1 | 71.4 |
係数表の要約
| 項 | 推定値 | 95%CI | p値 |
|---|---|---|---|
| 切片 β0 | -0.432 | -22.508 〜 21.644 | 0.969 |
| study_hours | 1.436 | 0.553 〜 2.320 | 0.002 |
| attendance_rate | 0.467 | 0.246 〜 0.688 | < 0.001 |
| prior_score | 0.362 | 0.182 〜 0.542 | < 0.001 |
モデル全体では F(3, 38) = 21.00, p < 0.001、調整済み R² = 0.594 でした。まずは『全体として説明できているか』を確認してから、各係数へ進むと整理しやすくなります。
R code
Rコードを順番に実行する
library(tidyverse)
dat <- read.csv("sample-data/sample_multiple_regression_scores.csv")
dat %>%
summarise(
n = n(),
mean_final = mean(final_score),
mean_study = mean(study_hours),
mean_attendance = mean(attendance_rate),
mean_prior = mean(prior_score)
)
head(dat)mod <- lm(
final_score ~ study_hours + attendance_rate + prior_score,
data = dat
)
summary(mod)
confint(mod)
# 説明変数どうしの関係をまず確認
cor(dat[, c("study_hours", "attendance_rate", "prior_score")])coef_tab <- as.data.frame(summary(mod)$coefficients)
coef_tab$term <- rownames(coef_tab)
ci_tab <- as.data.frame(confint(mod))
names(ci_tab) <- c("conf.low", "conf.high")
ci_tab$term <- rownames(ci_tab)
plot_tab <- coef_tab |>
left_join(ci_tab, by = "term") |>
filter(term != "(Intercept)")
library(ggplot2)
ggplot(plot_tab, aes(x = Estimate, y = reorder(term, Estimate))) +
geom_vline(xintercept = 0, linetype = 2) +
geom_point(size = 2.8) +
geom_errorbarh(aes(xmin = conf.low, xmax = conf.high), height = 0.18) +
labs(
x = "Adjusted coefficient estimate",
y = NULL,
title = "Multiple regression coefficients with 95% confidence intervals"
) +
theme_minimal(base_size = 13)
# 基本的な残差診断
par(mfrow = c(1, 2))
plot(mod, which = 1)
plot(mod, which = 2)Output
出力のどこを読めばよいか
重回帰では、モデル全体、各係数、95%信頼区間、調整済み R²の順に見ると整理しやすくなります。
p < 0.001
説明率の目安
p = 0.002
p < 0.001
この出力をどう解釈するか
このサンプルでは、重回帰モデル全体は有意であり(F(3, 38) = 21.00, p < 0.001)、調整済み R² は 0.594 でした。したがって、3つの説明変数をまとめることで、期末得点のばらつきの一部を説明できています。
各係数をみると、study_hours は β = 1.436、attendance_rate は β = 0.467、prior_score は β = 0.362 で、いずれも正の方向です。つまり、他の変数が同じ条件なら、学習時間・出席率・事前得点が高いほど期末得点も高い傾向が示されました。
Figure reading
係数プロットをどう読むか
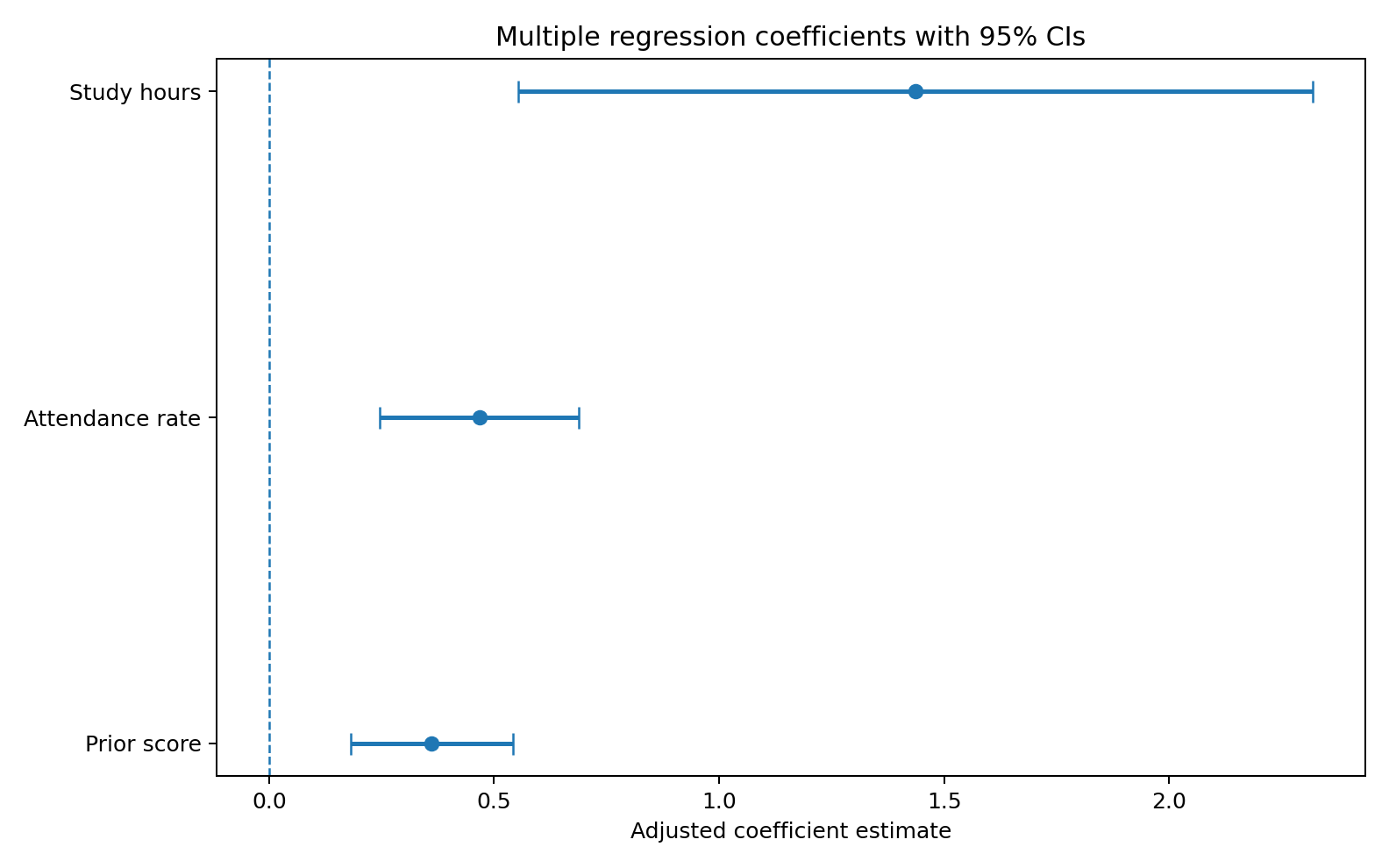
図1 重回帰分析における各説明変数の回帰係数と95%信頼区間
Figure 1. Adjusted coefficient estimates and 95% confidence intervals from the multiple regression model.
0 をまたぐかどうか
係数の95%信頼区間が 0 をまたがなければ、その係数は 0 と両立しにくいと判断しやすくなります。
符号の向きを見る
点が 0 より右なら正の関連、左なら負の関連です。今回の3変数はすべて右側にあり、正の方向でした。
単位が違うことに注意する
学習時間は「1時間」、出席率は「1%」、事前得点は「1点」あたりの係数なので、数字の大きさをそのまま単純比較しないようにします。
表と図を行き来する
係数表で正確な値を確認し、図で向きと不確実性をざっと把握すると、結果を読みやすく説明しやすくなります。
Report writing
レポートや論文での書き方
Japanese
結果記述例(日本語)
重回帰分析の結果、モデル全体は有意であった(F(3, 38) = 21.00, p < 0.001, 調整済み R² = 0.594)。学習時間(β = 1.436, 95%CI 0.553–2.320, p = 0.002)、出席率(β = 0.467, p < 0.001)、事前テスト得点(β = 0.362, p < 0.001)は、いずれも期末得点と正の関連を示した。
English
Report writing example
A multiple linear regression model was significant overall (F(3, 38) = 21.00, p < 0.001, adjusted R² = 0.594). Study hours (β = 1.436, 95% CI 0.553 to 2.320, p = 0.002), attendance rate (β = 0.467, p < 0.001), and prior test score (β = 0.362, p < 0.001) were positively associated with final exam scores after adjustment for the other predictors.
Caption
図表キャプション例
図1 重回帰分析における各説明変数の回帰係数と95%信頼区間
Figure 1. Adjusted coefficient estimates and 95% confidence intervals from the multiple regression model.
Common mistakes
よくあるミス
係数を単回帰と同じ感覚で読む
重回帰の係数は「他の変数を入れたうえでの条件つきの関連」です。単回帰の傾きと意味が少し違うので、調整済みであることを書き添えます。
単位の違う係数をそのまま比較する
1時間、1%、1点では単位が違います。効果の大きさを比べたいなら、標準化係数や変数のスケールも考慮します。
説明変数を増やせばよいと思ってしまう
目的や理論的背景のない変数を増やすと、解釈が難しくなり、サンプルサイズに対して不安定になることがあります。必要な変数を絞る視点も大切です。
FAQ
初心者がひっかかりやすい質問
Q. 説明変数がカテゴリでも重回帰は使えますか?
A. はい。ダミー変数に変換されるので、カテゴリ説明変数も一緒に入れられます。R では factor 型のまま lm() に入れてよいことが多いです。
Q. 係数が有意でない変数は必ず削除すべきですか?
A. 研究目的によります。理論的に重要な調整変数なら、p 値だけで機械的に外さないこともあります。
Q. 標準化係数は必要ですか?
A. 効果の大きさを相対的に比べたいときに便利ですが、まずは非標準化係数で『1単位増えるとどれだけ変わるか』を読めるようになるのが先です。
Q. 多重共線性はどう見ればよいですか?
A. 最初は説明変数間の相関行列を見て、必要に応じて VIF を確認します。非常に似た変数を同時に入れると、係数が不安定になります。
代替手法
代替手法・次のステップ
研究課題やデータ構造が少し変わると、選ぶべき手法も変わります。このテーマを土台にしつつ、どの条件で別の方法へ進むかを押さえておくと、分析計画が立てやすくなります。
単回帰分析
まずは1つの説明変数だけで関係を読みたいときは、単回帰から始める方が理解しやすいです。
ロジスティック回帰
目的変数が合格/不合格のような 0/1 データなら、線形回帰ではなくロジスティック回帰へ進みます。
交互作用・非線形項
説明変数どうしの組み合わせで効果が変わりそうなら交互作用項、関係が曲線的なら二乗項やスプラインも候補です。
参考資料
参考資料
このページの内容を深掘りしたいときに役立つ、公式ドキュメントと一次資料をまとめています。まずは関数の仕様、その次に補助的な可視化や読み方の資料を見ると理解しやすくなります。
運営と利用上の注意
このページの位置づけ
本サイトのトピックページは、Rによるデータ分析の学習支援とレポート作成の補助を目的としたオリジナル解説です。サンプルデータとコードは再現練習用に作成しているため、実データを扱う際には研究計画・前提条件・欠測・外れ値・尺度水準をあらためて確認してください。
編集方針
ページ本文は、標準的な統計手法、Rの公式ドキュメント、一次資料に近い参考文献を優先して整理しています。更新や訂正の方針は編集方針ページで公開しています。