Topic 18
相関行列のヒートマップ:相関構造の可視化
Correlation heatmap with top-pair summary and interpretation guide
複数変数の関連を一覧で見たいときの基本テーマです。どのペアが高相関か、正負の向きはどうか、多重共線性の懸念があるかを一目で把握できます。
このページでは、睡眠時間・ストレス・集中度・スクリーン時間・疲労感の5変数について、相関行列をヒートマップで可視化します。相関係数を表で眺めるだけでは見えにくい全体構造を、色で素早く把握できるようにします。
ヒートマップは便利ですが、相関は因果を意味しません。また、Pearson と Spearman の選択や外れ値の影響も意識する必要があります。
このページのゴール
- 相関行列ヒートマップが『複数変数間の関連を一覧で見る道具』だと説明できるようになる
- cor() で相関行列を作り、geom_tile() で可視化する流れを理解する
- 強い正相関・負相関のペアを抜き出して文章化できるようになる
- 多重共線性や因果解釈の誤りに注意できるようになる
Start here
まず押さえる4つのポイント
1. 相関行列は「一覧表」
複数変数の相関係数を一気に並べたものが相関行列です。ヒートマップにすると、高相関の場所が直感的に見えます。
2. 色の濃さは関連の強さ
正相関か負相関か、どの程度強いかを色で表します。まず濃いセルに注目すると読みやすくなります。
3. 強い相関は2変数ページで掘る
ヒートマップは全体像の把握に向きます。特定のペアを詳しく見るときは散布図へ進みます。
4. 相関は因果ではない
相関が高くても、一方が他方を原因としているとは限りません。第三の要因や逆方向もありえます。
Basics
何を見ているのか
相関行列ヒートマップは、複数の相関係数を表の代わりに色で配置した図です。変数数が増えたときに、全体構造を素早くつかむのに向いています。
今回の例
sleep_hours、stress_score、screen_time、concentration、fatigue の 5 変数を扱います。睡眠が長いほど疲労が少ないか、ストレスが高いほど集中が下がるか、といった関係をまとめて確認します。
どういう場面で役立つか
- 多重共線性がありそうな変数を探すとき
- PCA や重回帰の前に変数構造を把握したいとき
- アンケートや健康指標など、多変量データの全体像を要約したいとき
Checks
分析前に確認したいこと
Pearson と Spearman の選択
連続量で線形関係を想定するなら Pearson、順位的・単調関係や外れ値に配慮したいなら Spearman を検討します。
外れ値の影響
1つの外れ値で相関が大きく変わることがあります。必要なら散布図も確認します。
因果の言い過ぎ
ヒートマップは関連を示す図です。原因と結果を断定する図ではありません。
Data structure
サンプルデータの概要
72人分のデータで、5つの連続変数を扱います。
相関行列
| variable | sleep_hours | stress_score | screen_time | concentration | fatigue |
|---|---|---|---|---|---|
| sleep_hours | 1.0 | -0.5 | -0.5 | 0.7 | -0.7 |
| stress_score | -0.5 | 1.0 | 0.2 | -0.7 | 0.7 |
| screen_time | -0.5 | 0.2 | 1.0 | -0.4 | 0.2 |
| concentration | 0.7 | -0.7 | -0.4 | 1.0 | -0.5 |
| fatigue | -0.7 | 0.7 | 0.2 | -0.5 | 1.0 |
強い相関ペア上位
| pair | r |
|---|---|
| sleep_hours × fatigue | -0.7 |
| sleep_hours × concentration | 0.7 |
| stress_score × concentration | -0.7 |
| stress_score × fatigue | 0.7 |
| concentration × fatigue | -0.5 |
sleep_hours と fatigue は r = -0.74 の強い負相関でした。
Code
Rコード
cor() で相関行列を作り、as.table() で縦長データに直してから geom_tile() で可視化します。
library(dplyr)
library(tidyr)
library(ggplot2)
df <- read.csv("sample-data/sample_correlation_heatmap_wellbeing.csv")
mat <- df |>
select(-id) |>
cor(use = "pairwise.complete.obs", method = "pearson")
matheat_df <- as.data.frame(as.table(mat))
colnames(heat_df) <- c("var1", "var2", "r")
ggplot(heat_df, aes(x = var1, y = var2, fill = r)) +
geom_tile(color = "white") +
scale_fill_gradient2(low = "#3b82f6", mid = "white", high = "#ef4444", midpoint = 0) +
coord_equal() +
labs(x = NULL, y = NULL, fill = "r", title = "Correlation heatmap") +
theme_minimal(base_size = 13)Output
出力のどこを読むか
まずは絶対値の大きいセルに注目し、その後に符号(正か負か)を確認すると読みやすくなります。
sleep_hours × fatigue
sleep_hours × concentration
positive
negative
この結果をどうまとめるか
もっとも強い関連は sleep_hours と fatigue の負相関(r = -0.74)で、睡眠時間が長い人ほど疲労感が低い傾向がみられました。sleep_hours と concentration には正相関(r = 0.68)、stress_score と concentration には負相関(r = -0.68)がみられ、全体として睡眠・ストレス・集中のまとまりが確認できます。
重回帰へ進む場合は、sleep_hours と fatigue のような高相関ペアが多重共線性の候補になるかを意識しておくと役立ちます。
Figure reading
ヒートマップをどう読むか
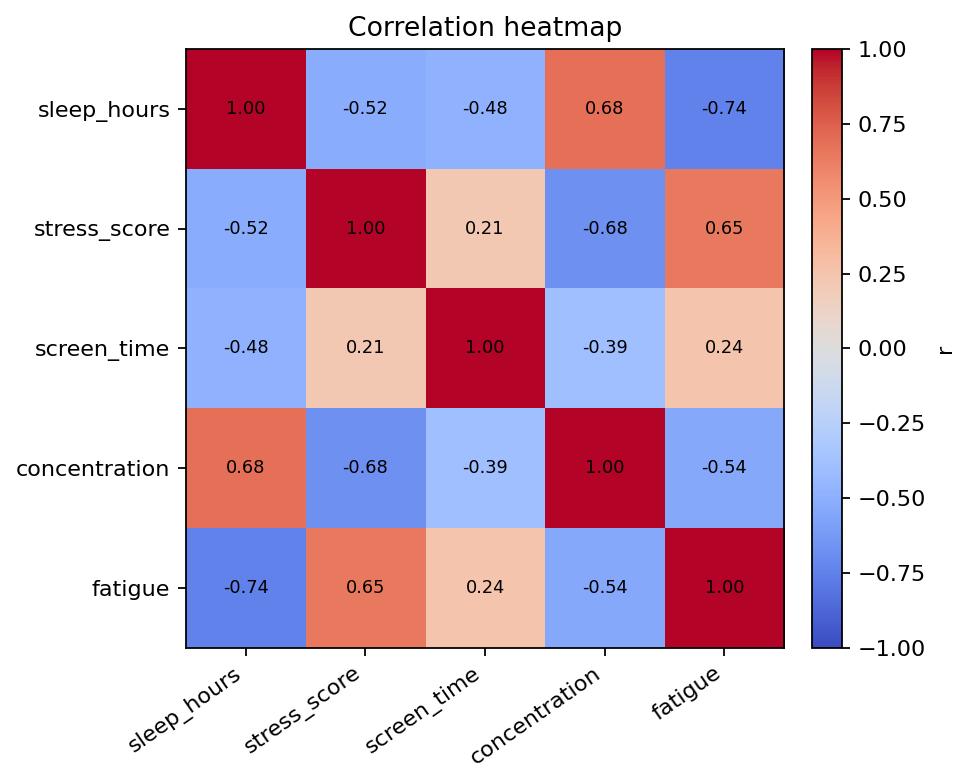
図1 複数変数の相関構造を示すヒートマップ
Figure 1. Heatmap of the correlation matrix.
対角は常に 1.00
同じ変数どうしの相関なので、対角セルは常に 1 になります。
色の濃い場所を探す
濃い赤や青のセルは、絶対値の大きい相関を示します。まずそこから読み始めるのがおすすめです。
左右対称になる
相関行列は対称なので、上三角だけを見る設計にすることもあります。
図だけで終わらない
強い相関が見つかったら、そのペアを本文で具体的に言い換えると伝わりやすくなります。
Report writing
レポートや論文での書き方
Japanese
結果記述例(日本語)
相関行列のヒートマップから、sleep_hours は fatigue と強い負相関(r = -0.74)を示し、concentration とは正相関(r = 0.68)を示した。一方、stress_score は concentration と負相関(r = -0.68)であり、複数の健康関連指標がまとまった構造を持つことが示唆された(図1)。
English
Report writing example
The correlation heatmap indicated that sleep_hours was strongly negatively correlated with fatigue (r = -0.74) and positively correlated with concentration (r = 0.68). In contrast, stress_score was negatively associated with concentration (r = -0.68). These results suggest a coherent structure among the well-being indicators (Figure 1).
Caption
図表キャプション例
図1 複数変数の相関構造を示すヒートマップ
Figure 1. Heatmap of the correlation matrix.
Common mistakes
よくあるミス
相関係数の絶対値だけで結論を出す
符号と文脈を見ずに「高い」「低い」だけで評価すると、実務上の意味づけが薄くなります。
有意差と混同する
ヒートマップは主に効果量の一覧です。p 値や信頼区間が必要なら別途計算します。
相関の高い変数を全部モデルに入れる
重回帰では多重共線性の原因になることがあるので、ヒートマップは事前チェックとしても有効です。
FAQ
初心者が迷いやすい点
Q. 相関が 0.7 なら強いと言えますか?
A. 分野や文脈によりますが、一般にはかなり強い関連として扱われることが多いです。ただし標本サイズや測定誤差も考慮します。
Q. 負の相関は悪い意味ですか?
A. いいえ。片方が増えるともう片方が減る方向の関係を示すだけで、良し悪しとは別です。
Q. カテゴリ変数にも使えますか?
A. 通常の Pearson 相関は連続変数向けです。カテゴリ変数には別の指標や手法を使います。
代替手法
代替手法・次の一歩
ヒートマップは全体像を俯瞰するのに向いていますが、研究質問によっては 2 変数の詳細確認や、複数変数を同時に調整する手法へ進む方が適切です。
散布図+回帰直線
特定の 2 変数の関係を詳しく見たいときは、散布図の方が外れ値や非線形性まで確認しやすくなります。
PCA
相関のある複数変数を少数の軸へ要約したいときは、ヒートマップから PCA に進む流れが自然です。
重回帰分析
別の要因を調整したうえで関連を評価したいときは、相関行列よりモデルベースの分析へ進みます。
参考資料
参考資料
このページは、相関行列の計算とヒートマップ可視化に直接関係する公式ドキュメントを中心にまとめています。まずは cor() の引数、次に geom_tile() と色スケールの指定方法を見ると流れがつかみやすくなります。
相関行列の計算
pairwise.complete.obs や Pearson / Spearman の違いは、実データの欠測や尺度水準に応じて使い分けます。
ヒートマップの可視化
色の中心を 0 に置くと、正の相関と負の相関を直感的に読み分けやすくなります。
運営と利用上の注意
このページの位置づけ
本サイトのトピックページは、Rによるデータ分析の学習支援とレポート作成の補助を目的としたオリジナル解説です。サンプルデータとコードは再現練習用に作成しているため、実データを扱う際には研究計画・前提条件・欠測・外れ値・尺度水準をあらためて確認してください。
編集方針
ページ本文は、標準的な統計手法、Rの公式ドキュメント、一次資料に近い参考文献を優先して整理しています。更新や訂正の方針は編集方針ページで公開しています。