Topic 16
主成分分析 PCA:バイプロット+固有値表
Principal component analysis with biplot and explained-variance table
複数の連続変数を、少数の主成分に要約して全体構造をつかみたいときの基本テーマです。相関のある変数群をまとめて眺める入口として使えます。
このページでは、5つの学習指標を 2〜3 個の主成分へ要約する主成分分析を扱います。PCA は『情報をなるべく失わずに次元を減らす』ための代表的な手法です。
初学者がつまずきやすい点は、負荷量の向き、標準化の必要性、寄与率の読み方です。ここでは、バイプロットと固有値表を並べて、どの変数がどの主成分に強く寄与しているかを確認できる構成にしています。
このページのゴール
- PCA が複数変数の共通パターンを少数の軸へ要約する手法だと説明できるようになる
- prcomp(scale. = TRUE) の基本的な使い方を理解する
- 固有値・寄与率・累積寄与率を読み、何成分を見るかの判断材料を得る
- バイプロットからサンプルの配置と変数ベクトルの向きを一緒に読む練習ができる
Start here
まず押さえる4つのポイント
1. PCA は「まとめ役の軸」を作る
相関のある複数変数を、できるだけ情報を失わずに少数の軸へ要約するのが PCA です。
2. PC1 は最も大きいばらつきの方向
第1主成分 PC1 は、データのばらつきを最も多く説明する方向です。PC2 は PC1 と直交しながら次に大きいばらつきを表します。
3. 負荷量は「どの変数が軸を作っているか」
負荷量が大きい変数ほど、その主成分の意味づけに強く関与します。符号は全体反転しても意味は同じです。
4. 単位が違うなら標準化
点数と時間のように尺度が違う変数を混ぜるなら、scale. = TRUE を付けて標準化するのが基本です。
Basics
PCA は何をしているか
PCA は、元の変数の線形結合として新しい軸を作り、その軸でデータのばらつきをよく表すように並べ替える手法です。
今回の例
5つの学習指標(math, logic, programming, writing, presentation)を対象に、学習者 54 人のデータをまとめます。数値を見ると、PC1 が 56.0%、PC2 が 30.2% を説明し、2成分で累積 86.2% をカバーしています。
どういうときに使うか
- 似た情報を持つ変数が多く、全体像を整理したいとき
- 散布図だけでは多変量構造が見えにくいとき
- クラスタリングや回帰の前に、変数構造を把握したいとき
Checks
分析前に確認したいこと
標準化が必要か
尺度がそろっていないと、分散の大きい変数が主成分を支配します。異なる単位が混ざるなら標準化が基本です。
外れ値の影響
PCA は分散に基づく手法なので、極端な外れ値があると軸の向きが大きく変わることがあります。
主成分数の決め方
累積寄与率だけでなく、解釈可能性も大切です。2成分で十分に構造がつかめるかを図と表で判断します。
Data structure
サンプルデータの概要
1行が1人、5列が学習指標です。今回は単位をそろえるため、PCA 実行時に標準化を行います。
固有値と寄与率
| Component | Eigenvalue | Explained | Cumulative |
|---|---|---|---|
| PC1 | 2.8 | 56.0% | 56.0% |
| PC2 | 1.5 | 30.2% | 86.2% |
| PC3 | 0.4 | 7.1% | 93.4% |
| PC4 | 0.2 | 3.7% | 97.1% |
PC1 / PC2 の負荷量
| variable | PC1 | PC2 |
|---|---|---|
| math | -0.8 | -0.4 |
| logic | -0.8 | -0.5 |
| programming | -0.8 | -0.2 |
| writing | -0.6 | 0.8 |
| presentation | -0.7 | 0.7 |
math・logic・programming は同じ向きにまとまっており、writing・presentation は PC2 方向の寄与が相対的に大きいことが分かります。
Code
Rコード
prcomp() の出力では、rotation が負荷量、x が主成分スコアです。
library(dplyr)
library(ggplot2)
df <- read.csv("sample-data/sample_pca_biplot_scores.csv")
pca_vars <- df |>
select(math, logic, programming, writing, presentation)
fit <- prcomp(pca_vars, center = TRUE, scale. = TRUE)
summary(fit)
fit$rotation[, 1:2] # loadings
head(fit$x[, 1:2]) # scores# スコアをデータフレームへ
scores <- as.data.frame(fit$x[, 1:2])
scores$id <- df$id
# バイプロット
biplot(fit, scale = 0, cex = 0.7)
# tidy な ggplot で描く場合は、scores と loadings を別々に作図する
Output
出力のどこを読むか
PCA の読み方は、(1) 寄与率、(2) 負荷量、(3) スコアの配置、の順に整理すると分かりやすくなります。
説明率
説明率
2成分累積
PC1 に強い寄与
この結果をどう読むか
PC1 は 56.0% の分散を説明し、math・logic・programming に高い負荷を持っていました。したがって PC1 は「分析・定量スキル」寄りの軸と解釈できます。
PC2 は 30.2% を説明し、writing と presentation の寄与が比較的大きく、表現・コミュニケーション寄りの軸とみなせます。2成分で累積 86.2% なので、まずは PC1 × PC2 の図で構造を把握するのが妥当です。
Figure reading
バイプロットをどう読むか
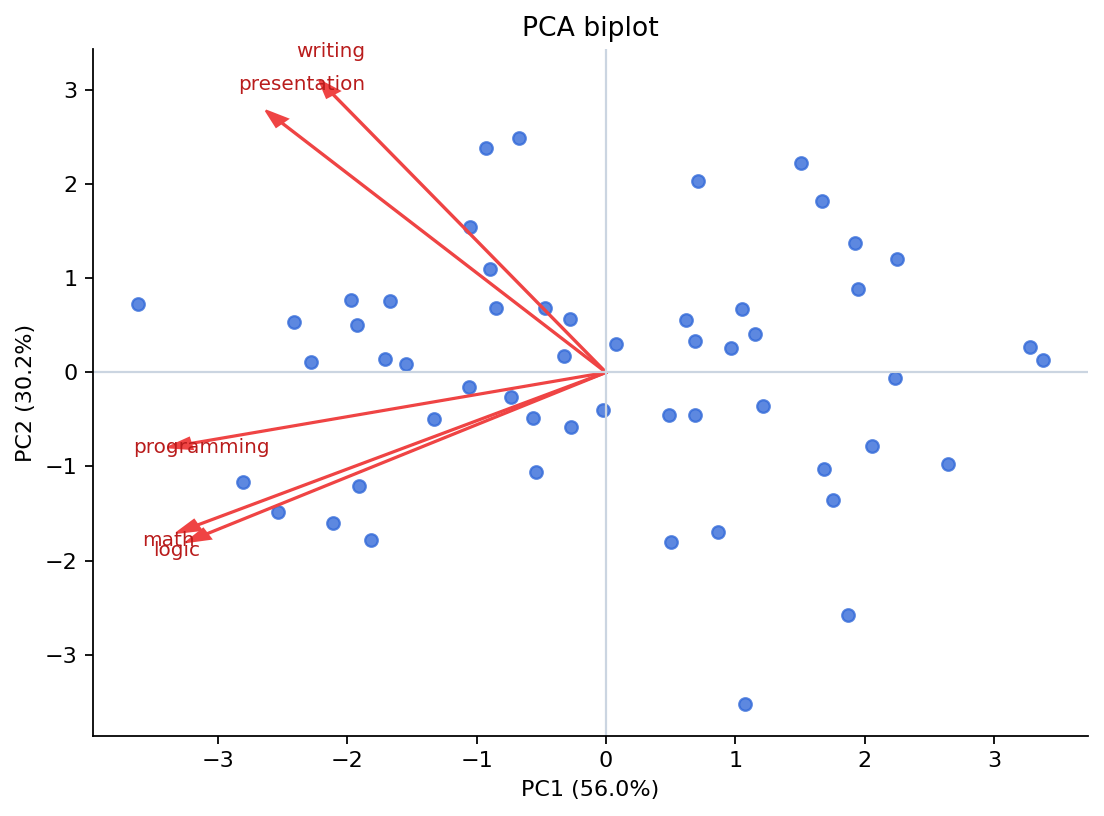
図1 PC1 と PC2 を用いた PCA バイプロット
Figure 1. PCA biplot based on PC1 and PC2.
点は観測、矢印は変数
点は個々の観測、赤い矢印は変数の寄与方向を示します。
矢印が近いほど似た変数
math と logic の矢印が近ければ、両者は似た方向の情報を持つと読めます。
原点から遠い点は特徴が強い
原点から離れた観測ほど、どこかの主成分方向に特徴が強いことを示します。
符号そのものには固執しない
主成分の向きは全体で反転しても意味は変わりません。大切なのは相対的な配置です。
Report writing
レポートや論文での書き方
Japanese
結果記述例(日本語)
主成分分析の結果、第1主成分(PC1)は全分散の 56.0%、第2主成分(PC2)は 30.2% を説明し、2成分で累積 86.2% を説明した。PC1 には math・logic・programming が強く寄与し、PC2 には writing・presentation が比較的大きく寄与した。図1のバイプロットは、学習指標が2つの主要な次元へ要約できることを示している。
English
Report writing example
Principal component analysis showed that PC1 and PC2 explained 56.0% and 30.2% of the total variance, respectively, accounting for 86.2% cumulatively. Math, logic, and programming contributed strongly to PC1, whereas writing and presentation contributed relatively more to PC2. The biplot in Figure 1 summarizes this two-dimensional structure.
Caption
図表キャプション例
図1 PC1 と PC2 に基づく主成分分析のバイプロット
Figure 1. PCA biplot based on PC1 and PC2.
Common mistakes
よくあるミス
寄与率だけで満足してしまう
何%説明したかだけでなく、どの変数がその軸を作っているかまで読んで初めて意味づけができます。
負荷量の符号を絶対視する
PCA の符号は軸全体で反転可能です。「正か負か」より、変数同士の相対関係に注目します。
標準化せずに単位の違う変数を混ぜる
変数のスケール差が大きいと、分散の大きな変数だけが主成分を支配しやすくなります。
FAQ
初心者が迷いやすい点
Q. PCA と因子分析は同じですか?
A. 似ていますが目的が違います。PCA は分散の要約、因子分析は潜在因子の推定に重心があります。
Q. 主成分は何個採用すればよいですか?
A. 累積寄与率、スクリープロット、解釈可能性を合わせて判断します。初学者向けにはまず 2 成分で図を見て、必要なら 3 成分目を追加します。
Q. バイプロットだけで十分ですか?
A. 図は有用ですが、固有値表と負荷量表も合わせて示すと、読み手にとってずっと親切です。
代替手法
代替手法・次の一歩
PCA は変数の共通した分散構造を少数の軸へ要約する入口です。目的が「高相関な変数を俯瞰したい」のか、「潜在概念を推定したい」のか、「観測を分けたい」のかで次の分析が変わります。
相関ヒートマップ
まずはどの変数ペアが高相関かを色で確認したいときの入り口です。PCA の前段としても使いやすい可視化です。
因子分析
背後にある潜在因子を推定したい研究では、分散要約を目的とする PCA より因子分析の方が研究目的に合うことがあります。
k-means クラスタリング
PCA で構造を眺めた後に、観測をいくつかのグループへ整理したいときの発展先です。
参考資料
参考資料
このページは、PCA の実行、標準化、バイプロットの基本に直接つながる一次資料を中心にまとめています。特に prcomp() の出力で、scores と loadings がどこに入るかを最初に確認するのがおすすめです。
PCA の実行
尺度の異なる変数を一緒に扱うときは、center と scale. の意味を先に理解しておくと読み違えが減ります。
図の読み方
寄与率の確認と PC1×PC2 の図の読み方を行き来しながら見ると、PCA の解釈が安定します。
運営と利用上の注意
このページの位置づけ
本サイトのトピックページは、Rによるデータ分析の学習支援とレポート作成の補助を目的としたオリジナル解説です。サンプルデータとコードは再現練習用に作成しているため、実データを扱う際には研究計画・前提条件・欠測・外れ値・尺度水準をあらためて確認してください。
編集方針
ページ本文は、標準的な統計手法、Rの公式ドキュメント、一次資料に近い参考文献を優先して整理しています。更新や訂正の方針は編集方針ページで公開しています。