Topic 24
多重コレスポンデンス分析 MCA:カテゴリ変数の構造をみる
Multiple correspondence analysis in R with FactoMineR and factoextra
複数のカテゴリ変数を一度に眺めて、どのカテゴリどうしが近いか、回答パターンがどのように分かれるかを見たいときの発展テーマです。PCA の『カテゴリ変数版に近い入口』として理解すると入りやすくなります。
多重コレスポンデンス分析(MCA)は、複数のカテゴリ変数からなるデータの全体構造を、少数の次元に要約して可視化する探索的手法です。質問紙、属性項目、学習スタイルのようなカテゴリ回答の整理に向いています。
このページでは、授業アンケート風のサンプルデータを使い、FactoMineR::MCA() で分析を行い、factoextra::fviz_mca_biplot() で個体とカテゴリを同時に可視化します。
Likert の分布を項目ごとに要約するページとは違い、ここでは複数項目の『全体の配置』を見ることに重点があります。
このページのゴール
- MCA が『複数のカテゴリ変数の全体構造を見る探索的手法』だと説明できるようになる
- 各列を factor にして MCA() に渡す基本フローを理解する
- 固有値・寄与率・カテゴリ座標表から、どの次元を見るかの感覚をつかむ
- バイプロットでカテゴリの近さ・原点からの離れ方・個体のまとまりを読めるようになる
- PCA、CA、FAMD との使い分けを大まかに整理できるようになる
Learn the idea
まず押さえるポイント
MCA は、複数のカテゴリ変数をまとめて可視化する探索的手法です。PCA が連続変数を扱うのに対し、MCA はカテゴリ変数の配置を見るための入口として使えます。
1 行が 1 回答者や 1 観測で、MCA では faint な点として描かれることが多いです。
major、participation、satisfaction のようなカテゴリ列をまとめて投入します。
多数のカテゴリ情報を少数の軸へ要約したものです。Dimension 1, 2 の意味を、寄与カテゴリから読むのが基本です。
個体とカテゴリを同じ図に重ね、どのカテゴリが近く配置されるかを探索的に確認します。
Basics
このページの分析の考え方
MCA は「いくつものカテゴリ変数を、2 次元くらいで眺めやすくする」ための手法です。質問紙や属性項目が多く、分割表をいくつも並べるだけでは全体像が見えにくいときに向いています。
PCA と何が違うか
PCA は連続変数、MCA はカテゴリ変数が対象です。Likert 尺度などを数値の平均としてではなく、カテゴリの配置として見たいときに MCA が役立ちます。
CA との違い
CA(対応分析)は 2 次元の分割表を扱う手法です。MCA は、カテゴリ変数が 3 列以上ある状況へ広げたものと考えると入りやすくなります。
このページで扱う流れ
- カテゴリ変数だけからなるサンプルデータを読み込む
- 各列を factor に変換する
MCA(..., graph = FALSE)で分析する- 固有値・寄与率を見て Dimension 1, 2 を確認する
fviz_mca_biplot()で個体とカテゴリの配置を読む
Interpretation checks
読むときの注意点
MCA は探索的な可視化手法なので、図の近さをそのまま因果や強い関連とみなさないことが大切です。カテゴリの頻度や rare level の扱いも結果に影響します。
rare category に引きずられる
ほとんど出ないカテゴリは原点から大きく離れて見えることがあります。まず各カテゴリの件数を確認し、必要ならまとめます。
数値列をそのまま混ぜる
MCA はカテゴリ変数向けです。連続変数を混ぜる場合は FAMD の方が適しています。
近い = 有意差あり、と読んでしまう
図上の近さは探索的な配置であり、検定の有意性そのものではありません。必要に応じて分割表や別の手法で確認します。
Data structure
データ構造
MCA は、1 行 1 回答者、各列がカテゴリ変数の wide 形式を基本にします。このページのサンプルでは、学科、学習時間、授業参加、自己効力感、出席、満足度などをカテゴリとして並べています。
入力データの例
| id | major | study_time | participation | satisfaction |
|---|---|---|---|---|
| 1 | Engineering | Mid | Sometimes | Mid |
| 2 | SocialSci | High | Often | Mid |
| 3 | Humanities | Mid | Sometimes | High |
| 4 | Engineering | Low | Rare | Low |
列の型は factor にそろえるのが基本です。
カテゴリ座標表の例
| category | Dim1 | Dim2 |
|---|---|---|
| High study_time | 1.35 | 1.05 |
| High confidence | 1.15 | 0.55 |
| Low satisfaction | -1.45 | -0.55 |
| Rare participation | -0.95 | -1.25 |
原点から離れたカテゴリほど、その次元の特徴づけに強く関わります。
Code
Rコード
下のコードでは、サンプル CSV を読み込み、カテゴリ列を factor に変換して MCA を実行します。まずは固有値表とバイプロットを出すところまで再現してください。
install.packages(c("tidyverse", "FactoMineR", "factoextra"))
library(tidyverse)
library(FactoMineR)
library(factoextra)
df <- readr::read_csv("sample-data/sample_mca_course_survey.csv", show_col_types = FALSE) %>%
mutate(across(-id, as.factor))
mca_fit <- MCA(df %>% select(-id), graph = FALSE)
eig_tbl <- as.data.frame(mca_fit$eig) %>%
tibble::rownames_to_column("dimension") %>%
setNames(c("dimension", "eigenvalue", "variance_percent", "cumulative_percent"))
eig_tblvar_coord <- as.data.frame(mca_fit$var$coord) %>%
tibble::rownames_to_column("category")
var_coord %>%
arrange(desc(abs(Dim.1)))
p <- fviz_mca_biplot(
mca_fit,
repel = TRUE,
col.var = "#2f67d8",
col.ind = "grey75",
alpha.ind = 0.45,
ggtheme = theme_minimal(base_size = 13)
)
print(p)
ggsave("mca_course_survey.png", plot = p, width = 8, height = 6)コードの最小ポイント
select(-id)にして、識別子列を分析から外しています。MCA(..., graph = FALSE)にすると、まず結果オブジェクトを手元に残しながら後で可視化できます。mca_fit$eigは次元ごとの情報量を確認する入口です。mca_fit$var$coordはカテゴリ点の座標表で、どのカテゴリがどちら側に寄るかを数値で確認できます。
Output
出力の読み方
MCA では、まず固有値・寄与率表で何次元目まで見るかの感覚をつかみ、その後にカテゴリ座標表とバイプロットで各次元の意味を読みます。
固有値・寄与率の例
| Dimension | Eigenvalue | % of variance | Cumulative % |
|---|---|---|---|
| Dim 1 | 0.284 | 28.4 | 28.4 |
| Dim 2 | 0.176 | 17.6 | 46.0 |
| Dim 3 | 0.131 | 13.1 | 59.1 |
最初の 2 次元で全体の 46% 程度を要約する、という読み方の例です。
カテゴリ座標表の見方
Dimension 1 で正方向に大きいカテゴリは同じ側に、負方向に大きいカテゴリは反対側に配置されます。たとえば High study_time と High satisfaction が同じ側にあり、Low satisfaction や Rare participation が反対側にあるなら、Dimension 1 を「学習参加の前向きさ」のようにラベルづける手がかりになります。
Figure reading
MCA バイプロットをどう読むか
MCA の図では、カテゴリ点どうしの近さ、原点からの距離、個体群の散らばりを見ます。カテゴリ点は濃く、個体点は薄く表示して、図の主役をカテゴリにすると読みやすくなります。
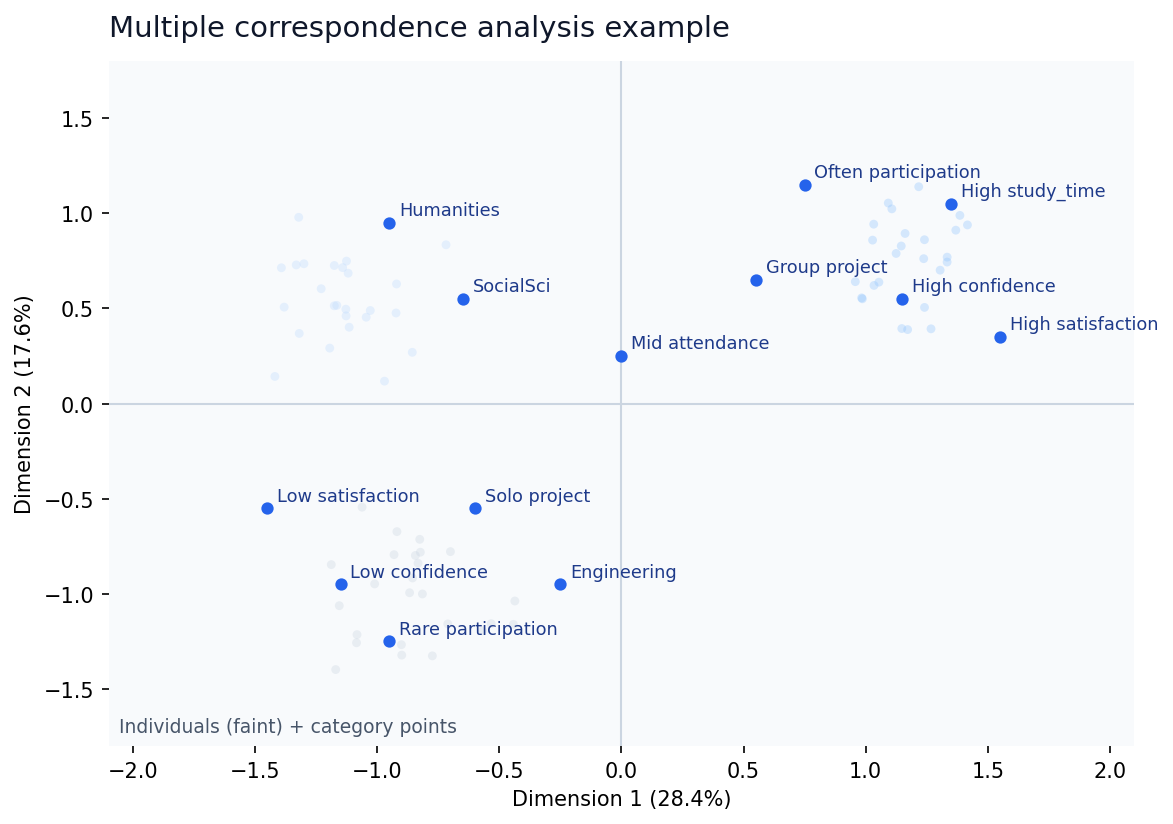
図1 授業アンケート風データに対する MCA バイプロット(例)
Figure 1. Example MCA biplot for a course-survey-like dataset.
近いカテゴリを読む
High study_time、High confidence、High satisfaction が近くにあれば、同じ個体群に現れやすい組み合わせとして読み始められます。
反対側のカテゴリを読む
Rare participation や Low satisfaction が反対側にあるなら、Dimension 1 が前向きさと消極性の対比を表している可能性があります。
原点に近い点は特徴が弱い
Mid attendance のように原点付近にあるカテゴリは、その次元の特徴づけに強くは効いていないと読めます。
個体点は雰囲気を見る
薄い個体点は、カテゴリの近くに集まる傾向を見るための補助です。個々の点を細かく読むより、まとまりを見るのが基本です。
Report writing
レポート用の結果記述例
MCA の記述では、対象となるカテゴリ変数、何次元まで見たか、各次元を特徴づけるカテゴリ、図の大まかな配置を書くと読み手に伝わりやすくなります。
日本語の書き方例
学習行動と授業経験に関する複数のカテゴリ変数を対象に、多重コレスポンデンス分析(MCA)を行った。第1次元と第2次元で全体の約46%を要約し、バイプロットでは High study_time、High confidence、High satisfaction が同じ側に配置される一方、Rare participation や Low satisfaction は反対側に位置した。これらの結果から、第1次元は学習参加の前向きさと消極性の対比を表す軸として解釈できる可能性が示唆された(図1)。
図1 授業アンケート風データに対する MCA バイプロット(例)
English writing example
Multiple correspondence analysis (MCA) was conducted on several categorical variables related to learning behavior and course experience. The first two dimensions summarized approximately 46% of the overall structure. In the biplot, categories such as High study_time, High confidence, and High satisfaction appeared on the same side, whereas Rare participation and Low satisfaction were located on the opposite side. These patterns suggest that Dimension 1 may represent a contrast between more engaged and less engaged response profiles (Figure 1).
Figure 1. Example MCA biplot for a course-survey-like dataset.
Common mistakes
よくあるミス
Likert を平均値だけで処理してしまう
項目の順序カテゴリとしての構造を見たいのに、最初から平均値へ還元すると、カテゴリの配置は見えません。目的に応じて集計方法を選びます。
カテゴリ件数を確認しない
まれなカテゴリが極端な位置に出て、図の印象を支配することがあります。まず件数表で rare level を確認します。
連続変数をそのまま入れる
MCA はカテゴリ変数向けです。数値変数が混ざるなら FAMD の方が自然です。
2 次元だけで全部を説明しようとする
最初の 2 次元は便利ですが、3 次元目以降にも重要な情報が残ることがあります。寄与率表も必ず確認します。
FAQ
FAQ
Q. Likert 尺度のデータにも MCA は使えますか?
A. はい。各項目をカテゴリとして扱うなら MCA の対象になります。ただし、順序情報をどう扱うかは研究目的に応じて検討が必要です。
Q. PCA とどちらを使うべきですか?
A. 変数が連続値なら PCA、カテゴリ変数なら MCA が基本です。両方混ざる場合は FAMD が候補になります。
Q. 何次元まで報告すればよいですか?
A. まずは第1・第2次元を中心に、寄与率とカテゴリの解釈可能性を見ます。必要なら第3次元以降も補足として示します。
代替手法
代替手法・次の一歩
MCA はカテゴリ変数の全体構造を見るのに便利ですが、研究質問によっては別の手法の方が直接的なこともあります。
参考資料
参考資料
MCA の入口としては、FactoMineR と factoextra の公式資料が最短です。混合データへ進みたい場合は FAMD の説明もあわせて確認すると流れがつながります。
MCA の実装
MCA() を含む主要な多変量手法がまとまっており、まずここを読むのが近道です。
可視化
fviz_mca_biplot()、fviz_mca_var() など、MCA の結果を ggplot2 ベースで整える関数が使えます。
発展先
連続変数とカテゴリ変数が混ざる場合は、MCA より FAMD を選ぶ方が自然です。
運営と利用上の注意
このページの位置づけ
本サイトのトピックページは、Rによるデータ分析の学習支援とレポート作成の補助を目的としたオリジナル解説です。サンプルデータとコードは再現練習用に作成しているため、実データを扱う際には研究計画・前提条件・欠測・外れ値・尺度水準をあらためて確認してください。
編集方針
ページ本文は、標準的な統計手法、Rの公式ドキュメント、一次資料に近い参考文献を優先して整理しています。更新や訂正の方針は編集方針ページで公開しています。