Topic 26
MCA のあとに続くクラスタリング:HCPC で回答パターンをまとめる
HCPC after MCA in R with FactoMineR
MCA でカテゴリ変数の全体配置を見たあとに、「では回答者はどんなまとまりに分かれるのか」をもう一歩踏み込んで見たいときの発展ページです。ここでは FactoMineR の HCPC を使い、MCA の座標を手がかりにクラスタリングする流れを整理します。
HCPC は Hierarchical Clustering on Principal Components の略で、因子分析や次元削減の結果を使って階層的クラスタリングを行う考え方です。カテゴリ変数中心のデータでは、MCA → HCPC の流れが自然な入口になります。
このページでは、授業アンケート風のカテゴリデータを使い、まず MCA で低次元表現を作り、その後で HCPC により回答者のまとまりとクラスタの特徴を確認します。
MCA ページと続けて読むと、「配置を見る」から「群としてまとめる」へ視点がつながります。
このページのゴール
- MCA のあとに HCPC を使う意味を説明できるようになる
- FactoMineR::HCPC() の最小実行フローを再現できる
- 樹形図・クラスターマップ・クラスタ記述表の読み方を理解する
- 探索的クラスタリングとして、断定しすぎない書き方を身につける
- k-means や FAMD + HCPC との使い分けの入口をつかむ
Learn the idea
まず押さえるポイント
HCPC は、次元削減した座標上で個体をまとめる発想のクラスタリングです。カテゴリ変数中心のデータでは、MCA で作った座標を手がかりにクラスタリングする、と考えると入りやすくなります。
まずカテゴリ変数の全体構造を低次元へ要約します。
その配置上で近い個体を階層的にまとめます。
クラスタ記述を見て、どの回答パターンがその群を特徴づけるかを確認します。
クラスタ数や解釈はデータ依存なので、決定的な真実として扱わないことが大切です。
Basics
分析の前提
HCPC は「次元削減の結果」と「階層的クラスタリング」を連結した探索的手法です。カテゴリ変数だけなら MCA のあとに使うのが自然で、量的変数だけなら PCA のあとに使う考え方が近くなります。
どんなときに向くか
- アンケートの回答者タイプを大まかに整理したい
- カテゴリ変数が多く、1つずつのクロス集計では全体像が見えにくい
- MCA 図の「まとまり」をもう少し形式的に扱いたい
どんなときに別手法か
- 量的変数だけなら PCA + HCPC や k-means が候補
- 質的・量的が混ざるなら FAMD + HCPC が候補
- クラス数を確率モデルで考えたいなら latent class analysis も候補
Checks
前提条件の確認
HCPC には p 値ベースの仮説検定の前提よりも、カテゴリの希少さ、クラスタ数の安定性、探索的解釈が重要です。
rare category に注意
極端に少ないカテゴリは、配置やクラスタ記述を不安定にすることがあります。
クラスタ数は唯一解ではない
推奨分割が出ても、別の切り方を見比べて解釈の妥当性を確認します。
ラベル付けは慎重に
「学習意欲が高い群」などの命名は便利ですが、根拠となるカテゴリ記述表を必ず確認します。
Data structure
データ構造
MCA と同じく、1 行が 1 回答者、列がカテゴリ変数です。このページでは、授業満足度、参加度、デバイス、学習スタイル、今後の計画を持つサンプルデータを使います。
入力表の例
| id | satisfaction | participation | device | study_style | plan |
|---|---|---|---|---|---|
| S01 | high | active | laptop | discussion | continue |
| S02 | middle | regular | tablet | practice | undecided |
| S03 | low | passive | smartphone | self-paced | review |
分析前の注意
- 文字列列は
as.factor()で factor 化する - id 列は説明変数ではないので除く
- 欠測が多い場合は、まず欠測の処理方針を決める
Code
Rコード
まず MCA を実行し、その結果を HCPC に渡します。最小の流れは MCA(..., graph = FALSE) → HCPC(..., graph = FALSE) です。
install.packages(c("tidyverse", "FactoMineR", "factoextra"))
library(tidyverse)
library(FactoMineR)
library(factoextra)
survey_df <- read_csv("sample-data/sample_mca_hcpc_course_survey.csv", show_col_types = FALSE) %>%
select(-id) %>%
mutate(across(everything(), as.factor))
res_mca <- MCA(survey_df, graph = FALSE)
res_hcpc <- HCPC(res_mca, graph = FALSE)
cluster_table <- res_hcpc$data.clust %>%
as_tibble(rownames = "row_id") %>%
count(clust, sort = TRUE)
print(cluster_table)
head(res_hcpc$data.clust)png("hcpc_tree.png", width = 900, height = 700)
plot(res_hcpc, choice = "tree", rect = TRUE)
dev.off()
png("hcpc_map.png", width = 900, height = 700)
plot(res_hcpc, choice = "map", draw.tree = FALSE)
dev.off()コードの最小ポイント
HCPC()は因子分析の結果を受け取るので、MCA オブジェクトをそのまま渡します。res_hcpc$data.clustにはクラスタ番号が入っており、後段の表や結合に使えます。- 最初は
choice = "tree"とchoice = "map"の2つを見られれば十分です。
Output reading
最初に読むべき出力
最初に見るのは、クラスタの件数表とクラスタ記述です。図だけ先に見てもよいのですが、各クラスタが何人で構成され、どのカテゴリが特徴なのかを表で押さえると解釈が安定します。
クラスタ件数の例
| cluster | n |
|---|---|
| 1 | 18 |
| 2 | 17 |
| 3 | 19 |
極端に小さい群が出たら、分割の安定性や rare category の影響も確認します。
クラスタ記述で見ること
- どのカテゴリが各クラスタに多いか
- cluster 1 と 2 の違いがどの項目で出るか
- 命名したくなる特徴に、複数の根拠があるか
Figure reading
クラスタープロットをどう読むか
この図は、MCA の第1・第2次元上に個体を置き、クラスタごとに色分けしたイメージです。近い点は似た回答パターンを持ちやすく、色のまとまりはクラスタの分離を示します。
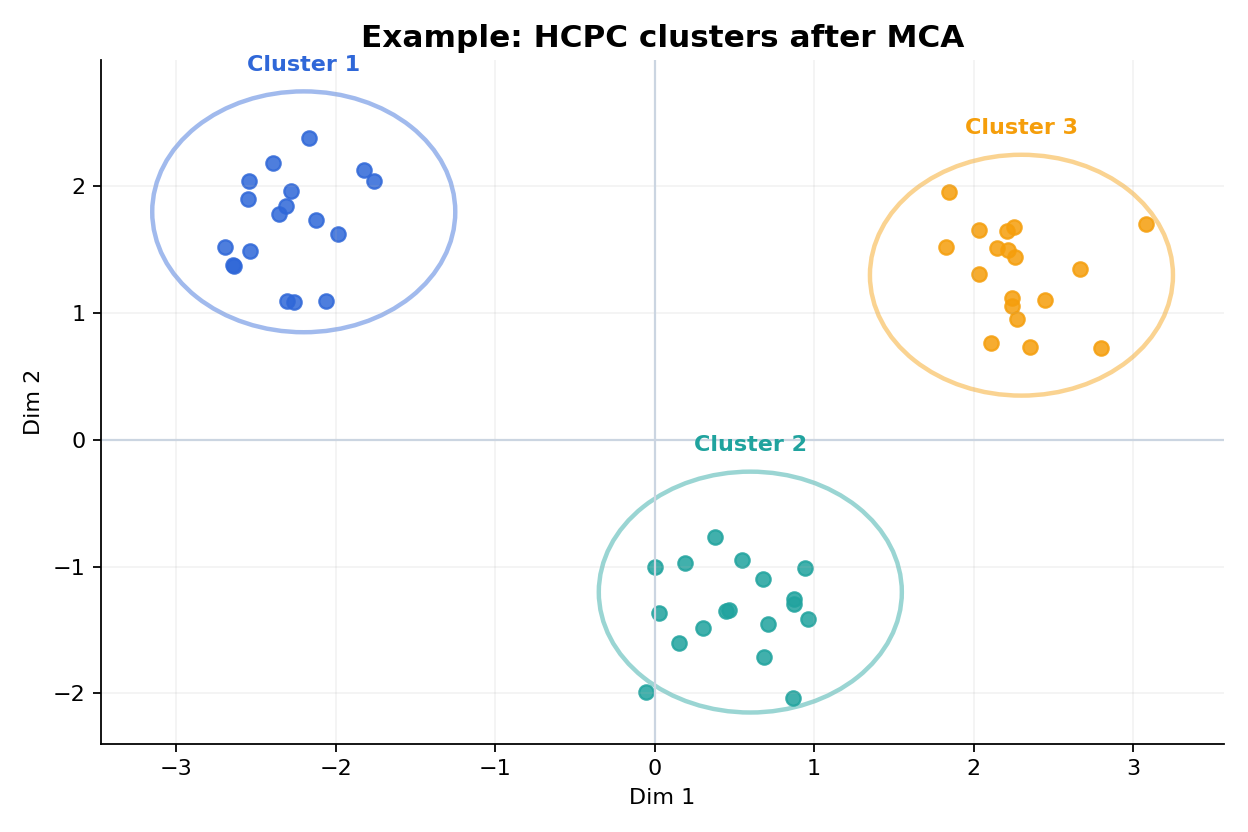
図1 MCA 後の HCPC によるクラスタープロット(例)
Figure 1. Example HCPC cluster map after MCA.
塊の分離を見る
色の塊が重なりすぎていないかを見ると、クラスタの分離の程度がつかめます。
軸の意味も戻って確認
第1・第2次元がどのカテゴリで特徴づけられるかは、MCA 側の寄与や座標表に戻って確認します。
外れた点に注意
クラスタ内でも遠く離れた点があれば、その回答者が例外的な組み合わせを持つ可能性があります。
樹形図とセットで読む
マップだけでなく、どの高さで切ったのかを樹形図で確認すると理解しやすくなります。
Writing
レポート文例
HCPC は探索的クラスタリングなので、群の存在を断定するより、「回答パターンのまとまりが示唆された」と書くと安全です。
日本語の書き方例
授業アンケート風のカテゴリデータに対して多重コレスポンデンス分析(MCA)を実施し、その結果に基づいて HCPC を行った。その結果、回答者は概ね 3 つのクラスタに分けられた。図1では、第1・第2次元上でクラスタごとのまとまりが観察され、クラスタ記述表からは、高満足・積極参加・継続志向の群、中程度の参加を示す群、低満足・復習志向の群が探索的に示唆された。
図1 MCA 後の HCPC によるクラスタープロット(例)
English example
Multiple correspondence analysis was first conducted on the categorical survey variables, followed by hierarchical clustering on principal components (HCPC). The results suggested an exploratory three-cluster structure among respondents. As shown in Figure 1, the clusters formed distinguishable groupings on the first two MCA dimensions, and the cluster descriptions indicated patterns roughly corresponding to highly engaged respondents, middle-range respondents, and lower-satisfaction respondents.
Figure 1. Example HCPC cluster map after MCA.
Mistakes
よくあるミス
クラスタを実体とみなす
クラスタはデータから作られた探索的な分割です。社会的実体と即断しないようにします。
MCA を飛ばして解釈する
HCPC の前段にある次元の意味を見ないと、色分けだけで物語を作ってしまいがちです。
rare category を放置する
非常に少ないカテゴリが、クラスタ記述を不安定にすることがあります。
FAQ
FAQ
k-means と何が違いますか?
HCPC は階層的クラスタリングで、樹形図とともに分割を見るのが特徴です。k-means は中心ベースで分割します。
カテゴリ変数と連続変数が混ざっている場合は?
FAMD のあとに HCPC を行う流れが近い選択肢になります。
クラスタ数は固定ですか?
いいえ。推奨分割はありますが、研究目的に照らして別の切り方も比較して検討します。
Alternatives
代替手法・次の一歩
HCPC は MCA のあとに続けやすい便利な発展形ですが、目的によっては別のクラスタリングや別の因子分析を使う方が自然です。
MCA に戻る
クラスタを作る前に、カテゴリの配置そのものを丁寧に読みたいときはこちらです。
一般的なクラスタリング
量的特徴量で単純に群分けしたいときは k-means が扱いやすいことがあります。
混合データ
質的・量的が混ざる場合は FAMD や MFA のあとに HCPC する流れが候補です。
よりモデルベースに
潜在クラス分析のようなモデルベースの群分けを使う選択肢もあります。
参考資料
参考資料
まず FactoMineR の HCPC 本体と plot.HCPC の説明を押さえ、その後に factoextra の可視化系を確認すると流れが見やすくなります。
HCPC の公式入口
HCPC は factor analysis の結果に対する agglomerative hierarchical clustering として説明されています。
可視化と補助ツール
factoextra は多変量解析結果の可視化を整理するための補助パッケージです。
前段の MCA
HCPC を読むときは、MCA の軸解釈とセットで見返すのが近道です。
運営と利用上の注意
このページの位置づけ
本サイトのトピックページは、Rによるデータ分析の学習支援とレポート作成の補助を目的としたオリジナル解説です。サンプルデータとコードは再現練習用に作成しているため、実データを扱う際には研究計画・前提条件・欠測・外れ値・尺度水準をあらためて確認してください。
編集方針
ページ本文は、標準的な統計手法、Rの公式ドキュメント、一次資料に近い参考文献を優先して整理しています。更新や訂正の方針は編集方針ページで公開しています。