Topic 17
k-means クラスタリング:クラスタ別散布図
k-means clustering with cluster profile table and colored scatter plot
似た特徴を持つ観測どうしを、事前に決めた k 個のクラスタへ分けたいときの基本テーマです。『群分けを発見する』という感覚をつかむ入口として使えます。
このページでは、study_hours・attendance_rate・final_score の3変数から、学習者を3つのクラスタへ分ける例を扱います。k-means は、クラスタ中心からの距離がなるべく小さくなるように観測を割り当てる、代表的なクラスタリング法です。
クラスタリングは推測統計の検定ではなく、データの構造を記述的に整理する手法です。『どんなタイプの学習者がいるか』を探索するときに向いています。
このページのゴール
- k-means が『似た観測を k 個にまとめる』手法だと説明できるようになる
- scale() と kmeans() を使った基本的なRコードを理解する
- クラスタ別の散布図とプロフィール表を行き来して解釈できるようになる
- k の決定、標準化、初期値依存といった注意点を押さえる
Start here
まず押さえる4つのポイント
1. k-means はグループを「見つける」
あらかじめ正解ラベルがあるのではなく、似た観測を自動的に k 個のグループへまとめる探索的手法です。
2. 距離に基づくので標準化が重要
大きな値の変数だけが支配しないよう、尺度が異なるときは標準化してから実行します。
3. k は分析者が決める
k-means は「クラスタ数」を先に指定します。エルボー法や解釈可能性を使って k を決めるのが基本です。
4. 結果は散布図とプロフィール表で読む
色分け散布図だけではなく、各クラスタの平均プロファイルを表で見ると意味づけしやすくなります。
Basics
k-means は何を最小化しているか
各観測を最も近いクラスタ中心へ割り当て、クラスタ内平方和が小さくなるように中心を更新していく手法です。
今回の例
学習時間、出席率、期末得点の3変数で学習者を3クラスタへ分けます。クラスタごとの平均プロフィールを見ると、低関与群・中間群・高関与群のようなパターンが見えてきます。
注意したいこと
- クラスタ数 k を自分で決める必要がある
- 初期値によって結果が多少変わることがある
- 外れ値の影響を受けやすい
Checks
分析前に確認したいこと
標準化するか
study_hours と final_score の単位が異なるので、そのまま距離を測ると値の大きい変数が効きすぎます。まず scale() を考えます。
k の根拠を書く
「3 にしたのは見た目でよさそうだから」でも探索分析としては出発点になりますが、エルボー法や解釈可能性も添えると丁寧です。
クラスタは真の群とは限らない
k-means はデータを説明しやすく分ける方法であり、自然界に本当に3種類が存在することを証明するわけではありません。
Data structure
サンプルデータの概要
1行が1人で、3つの数値変数を使います。ここでは k = 3 としてクラスタリングしました。
クラスタ別プロフィール
| cluster | n | study_hours | attendance_rate | final_score |
|---|---|---|---|---|
| 1 | 18.0 | 2.5 | 67.3 | 73.1 |
| 2 | 17.0 | 5.4 | 84.2 | 79.7 |
| 3 | 19.0 | 6.9 | 92.2 | 88.9 |
サイズの見方
クラスタサイズは 1群=18人, 2群=17人, 3群=19人 でした。極端に小さなクラスタがないので、例としては読みやすい構造です。
Cluster 1 は study_hours と final_score が低め、Cluster 3 はどちらも高めで、Cluster 2 がその中間に位置しています。
Code
Rコード
scale() → kmeans() → クラスタを元データへ戻す、の順で進めます。
library(dplyr)
library(ggplot2)
df <- read.csv("sample-data/sample_kmeans_clustering_students.csv")
x <- df |>
select(study_hours, attendance_rate, final_score) |>
scale()
set.seed(42)
fit <- kmeans(x, centers = 3, nstart = 20)
df$cluster <- factor(fit$cluster)
aggregate(df[, c("study_hours", "attendance_rate", "final_score")],
by = list(cluster = df$cluster), mean)ggplot(df, aes(x = study_hours, y = final_score, color = cluster)) +
geom_point(size = 2.8, alpha = 0.85) +
labs(
x = "Study hours",
y = "Final score",
color = "Cluster",
title = "k-means clustering result"
) +
theme_minimal(base_size = 13)Output
出力のどこを読むか
まずは各クラスタの平均プロフィールを見て、そのあと散布図で分離の仕方を確認します。
study_hours mean
attendance mean
final_score mean
preset clusters
この結果をどうまとめるか
Cluster 1 は学習時間 2.5 時間、出席率 67.3%、期末得点 73.1 点で、全体として低関与・低得点寄りの群でした。Cluster 3 はそれぞれ 6.9 時間、92.2%、88.9 点で、高関与・高得点寄りの群として読めます。
Cluster 2 は両者の中間に位置しており、段階的なプロフィールが見られます。したがって、このデータでは 3 つの学習パターンが探索的に示唆されたとまとめられます。
Figure reading
クラスタ別散布図をどう読むか
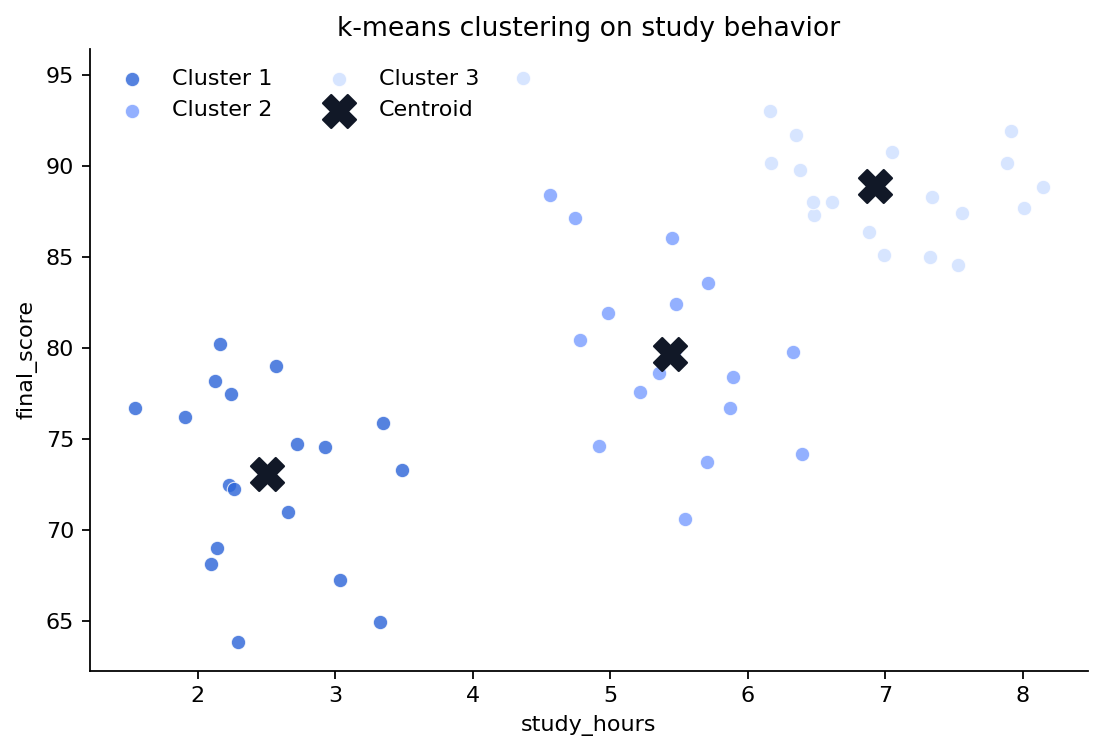
図1 k-means クラスタリング結果を示す色分け散布図
Figure 1. Scatter plot colored by cluster from the k-means solution.
色で群分けを見る
同じ色の点が同じクラスタに属します。色がある程度まとまって見えれば、分離しやすい構造と読めます。
2次元表示は投影である
今回は study_hours と final_score の2軸で見せていますが、クラスタリング自体は3変数で行っています。
中心点を確認する
大きな X はクラスタ中心です。各色の雲の真ん中付近にあるかを確認します。
境界が重なることもある
クラスタは完全に分離していなくても構いません。重なりの大きさもデータ構造の一部です。
Report writing
レポートや論文での書き方
Japanese
結果記述例(日本語)
標準化した学習指標に対して k-means クラスタリング(k = 3)を適用したところ、学習者は 3 つのプロフィールに分けられた。Cluster 1 は学習時間・出席率・期末得点が全体として低く、Cluster 3 はこれらが最も高かった。Cluster 2 は両者の中間に位置し、図1の散布図でも段階的な構造が確認できた。
English
Report writing example
Applying k-means clustering (k = 3) to the standardized learning indicators yielded three learner profiles. Cluster 1 was characterized by lower study hours, attendance, and final scores, whereas Cluster 3 showed the highest values on these variables. Cluster 2 represented an intermediate profile, as illustrated in Figure 1.
Caption
図表キャプション例
図1 k-means クラスタリング結果を示すクラスタ別散布図
Figure 1. Scatter plot colored by cluster from the k-means solution.
Common mistakes
よくあるミス
標準化せずに走らせる
尺度差の大きい変数が距離計算を支配しやすくなります。
k の理由を書かない
クラスタ数は分析者が決めるので、選んだ根拠を短くても添えると信頼性が増します。
クラスタ名を後付けしすぎる
「優秀型」など強いラベルを付けると、データ以上の意味づけになりやすいので慎重に書きます。
FAQ
初心者が迷いやすい点
Q. k はどう決めればよいですか?
A. エルボー法、シルエット、解釈可能性を組み合わせて考えます。授業レベルでは、複数の k を試して比較するだけでも学びになります。
Q. 毎回同じ結果になりますか?
A. 初期値に依存するので、set.seed() と nstart を指定して再現性を確保します。
Q. カテゴリ変数も混ぜられますか?
A. 基本の k-means は数値変数向けです。カテゴリを多く含む場合は別の距離や別手法を検討します。
代替手法
代替手法・次の一歩
k-means は「クラスタ数を先に決めて、球状に近い集まりを分ける」方法です。クラスタ数を事前に決めにくいときや、構造を樹形図で眺めたいときは別の方法が向きます。
階層的クラスタリング
クラスタ数を先に固定せず、樹形図を見ながらまとまりを考えたいときに向きます。
PCA と組み合わせる
変数が多いときは、PCA で次元を整理してからクラスタを考えると可視化しやすくなることがあります。
混合分布モデル
クラスタ境界の不確実性まで扱いたい、あるいは確率的に所属を考えたいときの発展的な選択肢です。
参考資料
参考資料
このページでは、kmeans() の基本仕様と、標準化・散布図可視化に関する公式資料を中心に整理しています。特に scale() と nstart の意味を押さえると、初学者でも結果の再現性を理解しやすくなります。
クラスタリング本体
変数の単位が異なる場合は、標準化を先に行うかどうかでクラスタ結果が大きく変わります。
可視化
散布図では、どの軸に何を置くかでクラスタの見え方が変わるため、解釈したい観点に合わせて軸を選びます。
運営と利用上の注意
このページの位置づけ
本サイトのトピックページは、Rによるデータ分析の学習支援とレポート作成の補助を目的としたオリジナル解説です。サンプルデータとコードは再現練習用に作成しているため、実データを扱う際には研究計画・前提条件・欠測・外れ値・尺度水準をあらためて確認してください。
編集方針
ページ本文は、標準的な統計手法、Rの公式ドキュメント、一次資料に近い参考文献を優先して整理しています。更新や訂正の方針は編集方針ページで公開しています。