Topic 8
ロジスティック回帰:0/1アウトカム × オッズ比表
Logistic regression with predicted probability curve and odds ratio table
目的変数が合格/不合格、成功/失敗のような 0/1 のときに使う基本テーマです。glm(family = binomial) の出力を読み、係数をオッズ比へ直して解釈する流れを身につけます。
このページでは、学習時間と合格/不合格のデータを使って、ロジスティック回帰の最初の一歩を学びます。サンプルでは 44 人分のデータを用い、study_hours が1時間増えると合格のオッズがどの程度変化するかを確認します。
このページのゴール
- ロジスティック回帰が『平均値』ではなく『確率』を扱うモデルだと理解する
- glm(..., family = binomial) の係数を exp() でオッズ比へ変換して読めるようになる
- 予測確率曲線を使って、説明変数とアウトカムの関係を図で説明できるようになる
- 二値アウトカムの結果を、日本語と英語の文章に落とし込めるようになる
Start here
まず押さえる4つのポイント
1. 0/1 アウトカムにはロジスティック回帰
目的変数が合格/不合格、成功/失敗、あり/なしのように2値なら、平均値を直接回帰するのではなくロジスティック回帰を使います。
2. 係数はまず log-odds の単位で出る
glm() の出力に出てくる係数は、そのままでは log-odds の単位です。初心者向けには、exp(係数) = オッズ比へ変換して読むと分かりやすくなります。
3. 予測確率曲線で関係をみる
回帰直線の代わりに、0から1のあいだを滑らかに変化する予測確率曲線を使って関係を可視化します。今回の例では、学習時間が長いほど合格確率が上がります。
4. オッズ比は 1 を基準に読む
オッズ比が 1 より大きければ正の関連、1 より小さければ負の関連です。この例では 1時間増えるごとの OR は 1.92 で、合格のオッズが上がる方向でした。
Basics
分析の概要と前提条件
どんなときに使うか
ロジスティック回帰は、0/1 のアウトカムの生起確率を説明したいときの基本手法です。今回の例では、study_hours が長いほど合格しやすいかをみます。
必要なデータ形式:1行が1観測で、passed のような 0/1 の列と、study_hours のような説明変数を持つ形です。
向いている場面
- 合格/不合格、成功/失敗などの二値アウトカムを扱うとき
- 説明変数が確率やオッズにどう関係するかを知りたいとき
- 予測確率を描いて結果を伝えたいとき
別の方法を考える場面
- 連続アウトカムなら単回帰・重回帰が基本です
- 説明変数もアウトカムもカテゴリなら、まずはカイ二乗検定で整理できます
- 時間と確率の関係が曲線的なら、多項式項やスプラインも検討します
logit はどう読むか
β1 を指数変換するとオッズ比になります。今回の推定では、study_hours の係数は 0.65 で、オッズ比は 1.92 でした。つまり、学習時間が1時間増えるごとに合格のオッズが約 1.92 倍になると解釈できます。
- アウトカムが 0/1 として正しく符号化されていること
- 観測どうしが独立していること
- 連続説明変数なら、logit と説明変数の関係が大きく崩れていないこと
- 完全分離が起きていないこと(ある範囲ですべて 0 / 1 になっていないこと)
Assumption check
前提条件はどう確認するか
ロジスティック回帰では、0/1 の符号化、データの重なり、極端な分離を特に意識すると、初学者のつまずきが減ります。
1. アウトカムの 0/1 を確認する
たとえば 1 = 合格、0 = 不合格 のように、どちらが1なのかを最初に明示します。逆だと、係数の符号の意味が反転します。
2. 説明変数の範囲に重なりがあるかみる
学習時間の低い群は全員不合格、高い群は全員合格のように完全に分かれすぎると、推定が不安定になります。
3. 予測確率曲線の形を確認する
学習時間が増えるほど確率がなめらかに上がるか、途中で不自然な段差がないかを図で見ます。
4. オッズ比のCIの幅もみる
OR が大きく見えても、95%CI が非常に広いと不確実性が大きいと分かります。点推定と区間推定をセットで読む癖をつけます。
Data structure
データの形をつかむ
サンプルデータは 44 人分で、passed は合格 = 1 / 不合格 = 0 です。全体の合格率は 38.6% でした。
サンプルデータの先頭
| id | study_hours | passed |
|---|---|---|
| 1 | 0.5 | 0 |
| 2 | 0.8 | 0 |
| 3 | 0.9 | 0 |
| 4 | 1.8 | 0 |
| 5 | 1.7 | 0 |
| 6 | 2.1 | 0 |
| 7 | 2.8 | 1 |
| 8 | 3.0 | 0 |
学習時間帯ごとの合格率
| hours_band | n | pass_rate |
|---|---|---|
| Q1 | 12 | 8.3% |
| Q2 | 11 | 27.3% |
| Q3 | 11 | 36.4% |
| Q4 | 10 | 90.0% |
四分位に分けて眺めると、学習時間帯が高いほど pass_rate が高くなる傾向があり、ロジスティック回帰の結果とも整合的です。
R code
Rコードを順番に実行する
library(tidyverse)
dat <- read.csv("sample-data/sample_logistic_regression_pass.csv")
# 0/1 の比率と説明変数の範囲を確認
dat %>%
summarise(
n = n(),
pass_rate = mean(passed),
min_hours = min(study_hours),
max_hours = max(study_hours)
)
head(dat)mod <- glm(passed ~ study_hours, data = dat, family = binomial())
summary(mod)
# 係数をオッズ比に変換
or_table <- cbind(
OR = exp(coef(mod)),
exp(confint.default(mod))
)
or_table
# 予測確率
dat$pred_prob <- predict(mod, type = "response")library(ggplot2)
newdat <- tibble(
study_hours = seq(min(dat$study_hours), max(dat$study_hours), length.out = 200)
)
newdat$pred_prob <- predict(mod, newdata = newdat, type = "response")
ggplot(dat, aes(x = study_hours, y = passed)) +
geom_jitter(height = 0.04, width = 0, alpha = 0.55) +
geom_line(data = newdat, aes(y = pred_prob), linewidth = 1.1) +
labs(
x = "Study hours",
y = "Probability of passing",
title = "Predicted probability from a logistic regression"
) +
theme_minimal(base_size = 13)Output
出力のどこを読めばよいか
ロジスティック回帰では、係数の符号、オッズ比、95%CI、z 値と p 値を順番に確認すると分かりやすくなります。
全体の合格率
1時間あたり
p < 0.001
Cox-Snell
この出力をどう解釈するか
このサンプルでは、study_hours の係数は 0.65 で、オッズ比に直すと 1.92(95%CI 1.33 〜 2.76)でした。したがって、学習時間が1時間増えるごとに、合格のオッズは約 1.92 倍になると解釈できます。
p 値は < 0.001 で、学習時間と合格の関連は統計的に支持されました。予測確率に直してみると、2時間のときの合格確率は約 4.8%、8時間では約 71.8% と見積もられます。
オッズ比表の例
| 指標 | 値 | OR | 95%CI(OR) |
|---|---|---|---|
| 切片 β0 | -4.28 | 0.01 | 0.00 〜 0.15 |
| study_hours | 0.65 | 1.92 | 1.33 〜 2.76 |
Figure reading
予測確率曲線をどう読むか
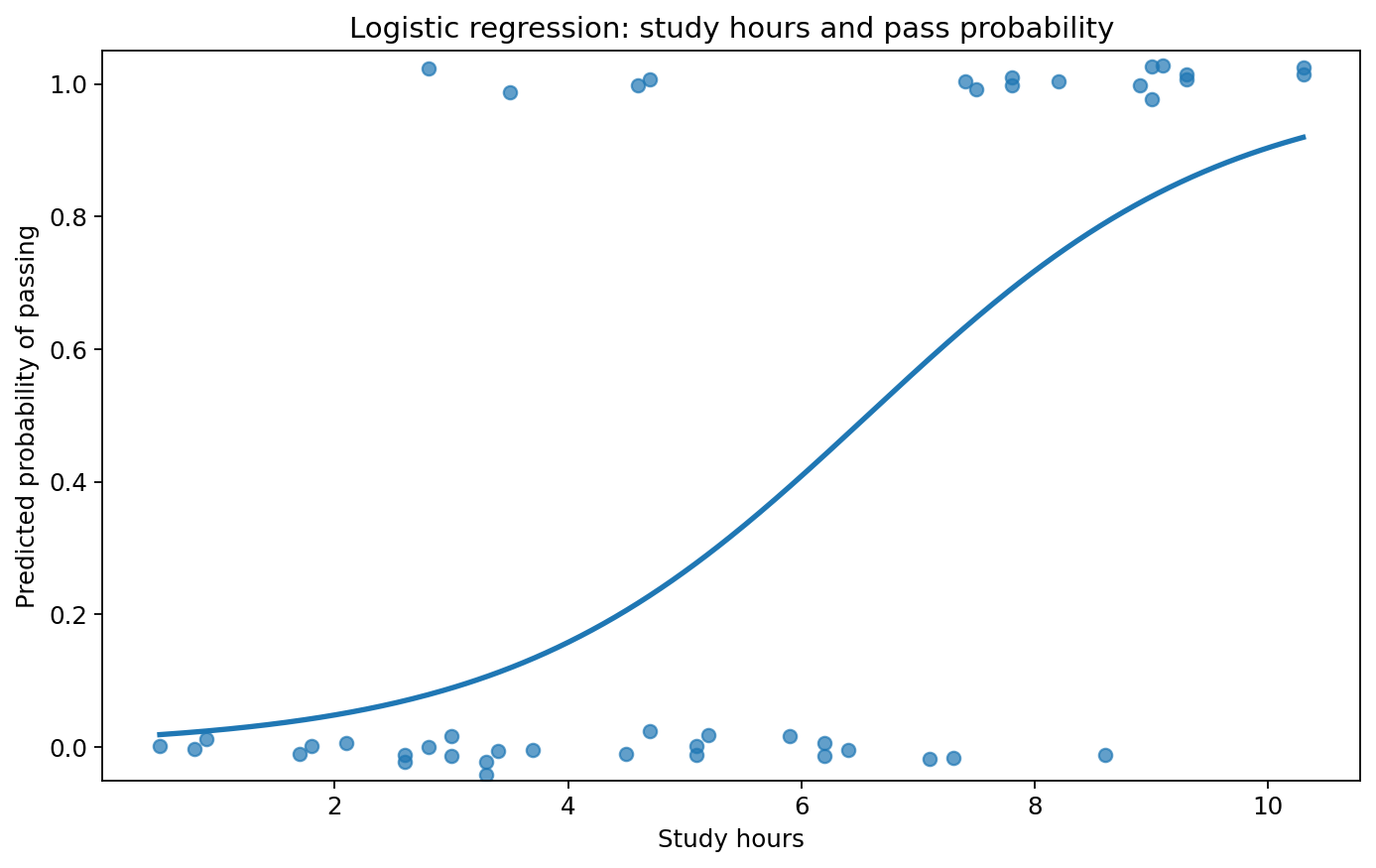
図1 学習時間と合格確率の関係を示すロジスティック回帰の予測曲線
Figure 1. Predicted probability of passing across study hours from the logistic regression model.
0 と 1 の点の重なり
点は実測値で、0 が不合格、1 が合格です。横方向の分布を見ると、学習時間が長い方に 1 が多くなる傾向があります。
S 字カーブ
ロジスティック回帰では、確率は直線ではなく S 字型に変化します。0 未満や 1 を超える確率にならないのが利点です。
中間域の変化に注目する
確率が 0.2〜0.8 のあたりでは、説明変数の変化に対して曲線が大きく動くので、解釈の中心になります。
確率とオッズを混同しない
図は確率、係数の指数変換はオッズ比です。どちらも大事ですが、意味は同じではありません。
Report writing
レポートや論文での書き方
Japanese
結果記述例(日本語)
ロジスティック回帰分析の結果、学習時間は合格と有意な正の関連を示した(β = 0.65, OR = 1.92, 95%CI 1.33–2.76, z = 3.51, p < 0.001)。図1に学習時間に応じた合格確率の予測曲線を示した。学習時間が長いほど、合格確率は高くなる傾向がみられた。
English
Report writing example
A logistic regression analysis showed that study hours were positively associated with passing the test (β = 0.65, OR = 1.92, 95% CI 1.33 to 2.76, z = 3.51, p < 0.001). Figure 1 shows the predicted probability curve, indicating that the probability of passing increased with longer study hours.
Caption
図表キャプション例
図1 学習時間と合格確率の関係を示すロジスティック回帰の予測曲線
Figure 1. Predicted probability of passing across study hours from the logistic regression model.
Common mistakes
よくあるミス
オッズ比をそのまま確率差だと思ってしまう
OR = 1.9 は「確率が 90%増える」という意味ではありません。オッズと確率は別物なので、必要なら予測確率も併記します。
0/1 の向きを明示しない
1 が何を表すかを書かないと、正の係数の意味が伝わりません。本文や表で「1 = pass」のように明示します。
分類精度だけでモデルを判断する
ロジスティック回帰では、係数、OR、CI、予測確率の形も重要です。閾値次第で accuracy は変わるので、それだけで結論を出しません。
FAQ
初心者がひっかかりやすい質問
Q. 二値アウトカムなら必ずロジスティック回帰ですか?
A. まずは基本形として有力です。説明変数もカテゴリだけで単純な比較なら、クロス集計とカイ二乗検定から始めることもあります。
Q. OR が 1.92 なら、ほぼ2倍合格しやすいのですか?
A. 「オッズ」が約2倍という意味です。確率の変化はベースラインによって変わるので、予測確率も併せて見ると誤解が減ります。
Q. 説明変数が複数でも同じですか?
A. 基本は同じです。複数変数を入れた多変量ロジスティック回帰では、各 OR は「他の変数を調整したうえで」の解釈になります。
Q. 線形性はどこに必要ですか?
A. 確率そのものではなく、logit(対数オッズ)と連続説明変数の関係が大きく崩れていないことを想定しています。
代替手法
代替手法・次のステップ
研究課題やデータ構造が少し変わると、選ぶべき手法も変わります。このテーマを土台にしつつ、どの条件で別の方法へ進むかを押さえておくと、分析計画が立てやすくなります。
カイ二乗検定
説明変数もカテゴリで、まずは単純な関連を分割表で見たいときはカイ二乗検定が分かりやすい出発点です。
多変量ロジスティック回帰
年齢や事前成績などを同時に調整したいなら、複数の説明変数を入れたモデルへ進みます。
非線形効果の追加
説明変数と logit の関係が直線的でなさそうなら、多項式項やスプラインで柔軟に表現する方法もあります。
参考資料
参考資料
このページの内容を深掘りしたいときに役立つ、公式ドキュメントと一次資料をまとめています。まずは関数の仕様、その次に補助的な可視化や読み方の資料を見ると理解しやすくなります。
運営と利用上の注意
このページの位置づけ
本サイトのトピックページは、Rによるデータ分析の学習支援とレポート作成の補助を目的としたオリジナル解説です。サンプルデータとコードは再現練習用に作成しているため、実データを扱う際には研究計画・前提条件・欠測・外れ値・尺度水準をあらためて確認してください。
編集方針
ページ本文は、標準的な統計手法、Rの公式ドキュメント、一次資料に近い参考文献を優先して整理しています。更新や訂正の方針は編集方針ページで公開しています。