Topic 25
感情分析の入門:Jane Austen 作品 × tidytext × 感情推移図
Beginner sentiment analysis in R with Jane Austen and tidytext
単語頻度の棒グラフの次に試しやすいのが、語を positive / negative などの感情語彙へ対応づけて、章や区間ごとの感情の流れを見る感情分析です。このページでは、Jane Austen の Pride & Prejudice を使って、lexicon ベースの最初の感情分析を再現します。
ここで扱うのは、機械学習モデルではなく、辞書(lexicon)を使った素朴で分かりやすい感情分析です。まずは「単語を sentiment 辞書と突き合わせ、positive と negative を数える」という考え方をつかみます。
章ごとの集計にして図へすると、作品全体でどの区間に相対的に positive / negative 語が多いかを探索的に眺められます。最初は正確な感情推定というより、「テキストにもう一つの要約軸を足す」練習として考えるのが安全です。
頻度表や共起ネットワークのページと合わせると、語の多さ・語のつながり・語の感情極性という三つの見方を並べて比較できます。
このページのゴール
- lexicon ベースの感情分析が何をしているかを説明できるようになる
- get_sentiments("bing") と inner_join() を使って感情語を付与できるようになる
- 章ごとの positive / negative / net sentiment を集計できるようになる
- 感情推移図を読み、頻度表との違いを説明できるようになる
- 感情分析の限界(否定、皮肉、文脈依存)を最低限理解する
Learn the idea
まず押さえるポイント
感情分析の最初の入口は、単語を辞書と突き合わせることです。辞書に positive / negative などのラベルが付いていれば、各章や各文書にどれだけ positive 語・negative 語が出たかを数えられます。
まずは学習済みモデルよりも、感情語辞書との join で考えると流れがつかみやすくなります。
章、段落、10行ごとの区間など、どの単位で数えるかを先に決めます。
positive - negative のような差を作ると、推移図として見やすくなります。
否定表現、皮肉、文脈依存は苦手です。探索的要約として使うのが基本です。
Basics
分析の前提
このページでは、tidytext の lexicon を使うもっとも素朴な感情分析を扱います。文そのものを学習モデルへ入れるのではなく、単語へ分解したあとで sentiment 辞書と結合する、という考え方です。
どんな問いに向くか
- 作品や記事のどの区間で negative 語が増えるかをざっくり見たい
- 作品間や章間で感情語の偏りを比べたい
- text mining の最初の要約として、頻度表とは別軸の図を置きたい
どこに注意するか
- not good のような否定は、単語単位の辞書法だけでは扱いにくい
- 同じ語でも文脈で意味が変わる
- 頻度が高い章は absolute count が大きくなりやすいので、必要に応じて標準化も考える
Checks
前提条件の確認
感情分析では統計検定の前提というより、集計単位と辞書の選択が重要です。同じテキストでも、章単位・段落単位・固定長区間で結果の見え方が変わります。
単位の一貫性
章ごとに数えるのか、10行ごとに数えるのかを混ぜないようにします。
stopwords の扱い
まずは stopwords を除いてから sentiment 辞書と結合すると、ノイズが減ります。
辞書の選択
Bing は positive / negative の2値で直感的、AFINN は数値スコア、NRC は感情カテゴリも扱えます。
Data structure
データ構造
Jane Austen のテキストは、まず book と text を持つ表として取得します。その後、章番号を付け、unnest_tokens() で 1 行 1 単語へ変換するのが基本の流れです。
分析前の形
| book | text |
|---|---|
| Pride & Prejudice | chapter 1 |
| Pride & Prejudice | it is a truth universally acknowledged ... |
| Pride & Prejudice | however little known the feelings ... |
分析に入る直前の形
| chapter | word | sentiment |
|---|---|---|
| 1 | truth | positive / negative なし |
| 1 | universally | なし |
| 1 | happy | positive |
sentiment 辞書に載っていない単語は join 後に落ちるので、感情表には残りません。
Code
Rコード
まずは章番号を作り、次に単語へ分解し、最後に get_sentiments("bing") と join して章ごとの positive / negative / net を集計します。
install.packages(c("tidyverse", "tidytext", "janeaustenr", "ggplot2", "stringr"))
library(tidyverse)
library(tidytext)
library(janeaustenr)
library(ggplot2)
library(stringr)
books <- austen_books() %>%
filter(book == "Pride & Prejudice") %>%
mutate(
line_number = row_number(),
chapter = cumsum(str_detect(text, regex("^chapter\s+[0-9ivxlc]+$", ignore_case = TRUE)))
) %>%
filter(chapter > 0)
sentiment_by_chapter <- books %>%
unnest_tokens(word, text) %>%
anti_join(get_stopwords(), by = "word") %>%
inner_join(get_sentiments("bing"), by = "word") %>%
count(chapter, sentiment) %>%
tidyr::pivot_wider(names_from = sentiment, values_from = n, values_fill = 0) %>%
mutate(net = positive - negative)
print(head(sentiment_by_chapter, 10))sentiment_plot <- sentiment_by_chapter %>%
slice_head(n = 20) %>%
ggplot(aes(chapter, net)) +
geom_col(fill = "#3c78d8") +
labs(
title = "Net sentiment by chapter: Pride & Prejudice",
x = "chapter",
y = "positive - negative"
) +
theme_minimal(base_size = 13)
print(sentiment_plot)
ggsave("sentiment_chapter_plot.png", plot = sentiment_plot, width = 7, height = 4.5)コードの最小ポイント
inner_join(get_sentiments("bing"), by = "word")で感情語だけを残します。pivot_wider()後にnet = positive - negativeを作ると図にしやすくなります。- 章ではなく 80 行ごと・100 単語ごとなどの固定長区間に替えても同じ考え方で動きます。
Output reading
最初に読むべき出力
最初に見るのは、章ごとの positive / negative の件数表です。ここで 何を数えたのか が分かると、あとから図を読んだときに解釈が安定します。
感情件数表の例
| chapter | positive | negative | net |
|---|---|---|---|
| 1 | 18 | 13 | 5 |
| 2 | 24 | 12 | 12 |
| 3 | 10 | 13 | -3 |
| 4 | 21 | 14 | 7 |
net が正なら positive 語が相対的に多く、負なら negative 語が多いと読めます。
ここで確認すること
- 章番号が意図どおり振れているか
- 極端に語数が少ない章が混ざっていないか
- positive / negative の両列が作られているか
- net の符号が直感と大きくずれていないか
Figure reading
感情推移図をどう読むか
この図では、棒が上に伸びるほど positive 語が、下に伸びるほど negative 語が相対的に多かったことを示します。まずは山と谷の位置を見ると読みやすくなります。
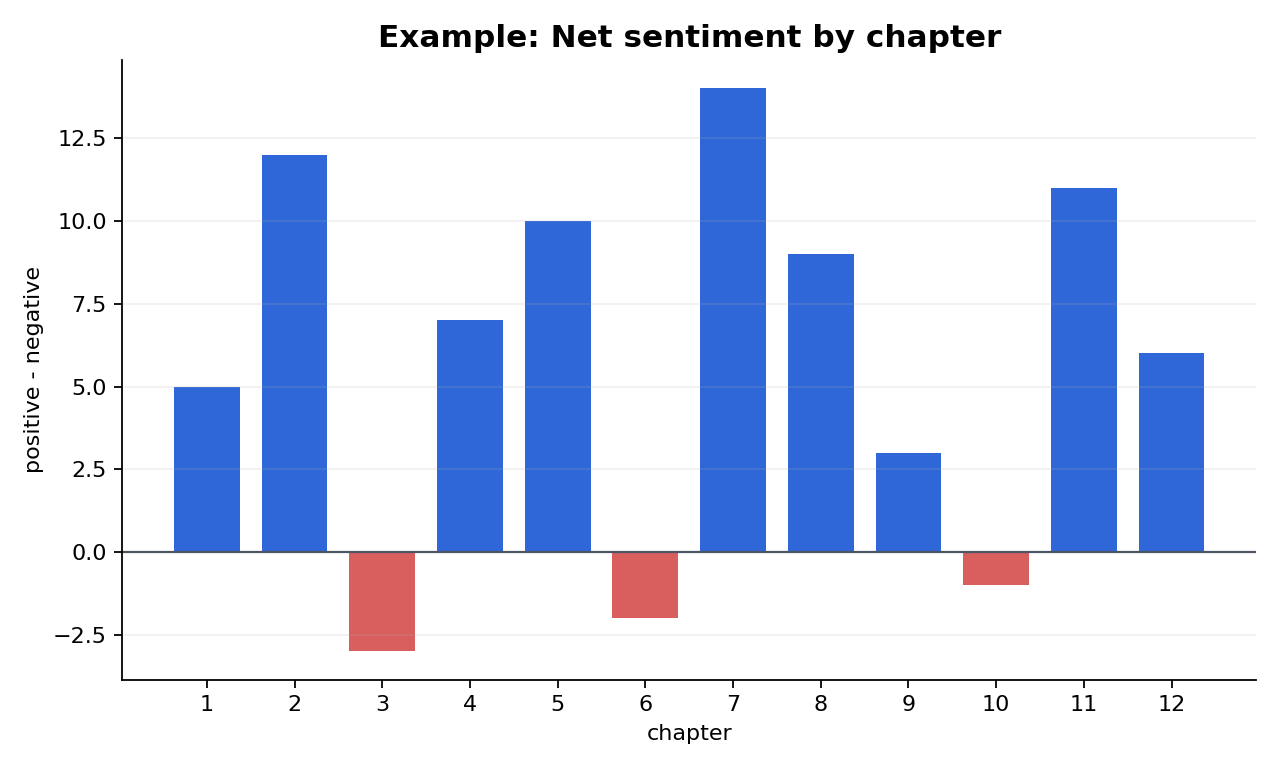
図1 Pride & Prejudice における章別の net sentiment(例)
Figure 1. Example net sentiment by chapter in Pride & Prejudice.
まず符号を見る
0 より上なら positive 優位、下なら negative 優位という読み方をします。
変化点を見る
章 2 → 3 のように符号が反転する場所は、語彙の雰囲気が切り替わる箇所として注目できます。
高さだけで断定しない
高い棒は「その章が幸福だった」証明ではなく、辞書上 positive 語が多かったことを示すだけです。
次の一歩へつなぐ
気になる章があれば、原文を読み返すか、共起ネットワークで関連語を見に行くと理解が深まります。
Writing
レポート文例
感情分析は探索的な要約として書くのが安全です。断定的に「作品の感情そのもの」を述べるより、辞書ベースの結果として表現します。
日本語の書き方例
Jane Austen の Pride and Prejudice を対象に、辞書ベースの感情分析を行った。章ごとの positive 語と negative 語の出現件数を集計したところ、章によって net sentiment(positive − negative)に変動がみられた。図1では、章2や章7で相対的に positive 語が多く、章3では negative 語がやや優位であったことが示されている。これらの結果は、作品内の語彙の雰囲気が章ごとに変化する可能性を示す探索的所見として解釈される。
図1 Pride and Prejudice における章別の net sentiment(例)
English example
A lexicon-based sentiment analysis was conducted on Pride and Prejudice. Positive and negative words were counted for each chapter, and net sentiment was calculated as positive minus negative. As shown in Figure 1, the balance of sentiment words varied across chapters, with relatively more positive words in Chapters 2 and 7 and a slightly more negative balance in Chapter 3. These findings should be interpreted as an exploratory summary of lexical tone rather than a definitive measure of narrative sentiment.
Figure 1. Example net sentiment by chapter in Pride and Prejudice.
Mistakes
よくあるミス
辞書に入っていない語を見落とす
重要な語でも辞書に無ければ集計に出ません。感情分析は text 全体の一部だけを見ています。
章の切り方がずれる
chapter 行の検出がうまくいかないと、集計単位が崩れます。最初に table を確認してください。
結果を断定的に言い切る
辞書ベースの結果は探索的要約です。物語の意味内容そのものと同一視しないようにします。
FAQ
FAQ
Bing 以外の辞書も使えますか?
はい。AFINN は数値スコア、NRC は感情カテゴリを含みます。最初は Bing が最も直感的です。
日本語でも同じコードでできますか?
考え方は同じですが、トークン化と辞書が別になります。日本語では形態素解析や別の辞書が必要です。
章の長さが違ってもよいですか?
よいですが、長さの差が大きいと absolute count は影響を受けます。必要なら割合や1000語あたりへ標準化します。
Alternatives
代替手法・次の一歩
感情分析はテキストの要約軸の一つです。目的に応じて、頻度、共起、特徴語、トピックモデルへ切り替えると見えるものが変わります。
より基本に戻る
まず語の多さだけを確認したいなら、頻度表と棒グラフが最も素直です。
語のつながりを見る
感情の上下だけでなく、「どの語とどの語が一緒に現れやすいか」を見たいときに向きます。
高速前処理や DFM
大量文書を扱うときは tokens → dfm の流れへ移ると高速に進めやすくなります。
さらに発展
文書集合の背後にある話題構造を見たいときは、トピックモデルが発展先です。
参考資料
参考資料
まずは tidytext の Introduction と sentiment 関連ドキュメントを押さえると、このページのコードの意味が見通しやすくなります。
tidytext の基本
tidytext は text を tidy data として扱えるようにするパッケージで、sentiment lexicon を join して数える流れがこのページの基盤です。
語彙辞書と stopwords
janeaustenr は Jane Austen の 6 作品を、text mining に使いやすい形で提供しています。
次の発展先
高速前処理や文書行列、さらにトピックモデルへ進むと、感情分析以外の text mining の道具が増えます。
運営と利用上の注意
このページの位置づけ
本サイトのトピックページは、Rによるデータ分析の学習支援とレポート作成の補助を目的としたオリジナル解説です。サンプルデータとコードは再現練習用に作成しているため、実データを扱う際には研究計画・前提条件・欠測・外れ値・尺度水準をあらためて確認してください。
編集方針
ページ本文は、標準的な統計手法、Rの公式ドキュメント、一次資料に近い参考文献を優先して整理しています。更新や訂正の方針は編集方針ページで公開しています。