Topic 23
共起ネットワーク:Jane Austen 作品 × widyr × ggraph
Co-occurrence network in R with tidytext, widyr, and ggraph
単語頻度の棒グラフから一歩進んで、どの語どうしが一緒に現れやすいかを『つながり』として見たいときの発展テーマです。テキスト分析とネットワーク分析を橋渡しする入門〜初級上のページとして使えます。
共起ネットワークでは、単語をノード、同じ文脈や同じ窓の中で一緒に現れた関係をエッジとして表します。頻度表では見えにくい『誰と誰がセットで現れやすいか』を図として眺められるのが利点です。
このページでは、Jane Austen の Pride & Prejudice を使い、10 行ごとの section を共起の単位にしながら、pairwise_count() で単語ペアを数え、ggraph() でネットワーク図にします。
単語頻度ページを終えたあとに進むと、トークン化 → stopwords 除去 → 単語ペア → ネットワーク図という流れが自然に理解できます。
このページのゴール
- 共起ネットワークが『単語ペアの頻度表をグラフ化したもの』だと理解する
- どの単位で共起を数えるか(行、文、段落、窓)を意識できるようになる
- widyr::pairwise_count() を使って共起ペア表を作れるようになる
- igraph と ggraph で共起ネットワーク図を描き、読み方の型をつかむ
- 頻度の高い単語と、つながりの中心にいる単語が必ずしも同じではないことを理解する
Learn the idea
まず押さえるポイント
共起ネットワークは、どの単語がどの単語と一緒に現れやすいかを、点と線で表す可視化です。単語頻度の次の一歩として、文脈の近さをざっくり眺めたいときに向いています。
トークン化した 1 行 1 単語のデータが出発点です。まず tidytext の流れを理解しておくと入りやすくなります。
文、行、章、段落、10行ごとの窓など、何を「同じ文脈」とみなすかを先に決めます。
同じ窓に出た語の組み合わせを数えると、共起ペア表ができます。これがネットワーク図の元になります。
よく結びつく語を太い線や近い位置で見せることで、人物名や関係語のまとまりを探索的に読めます。
Basics
このページの分析の考え方
頻度表では「どの語が多いか」は分かりますが、「どの語どうしが一緒に現れるか」は分かりません。共起ネットワークは、その不足を補うための発展的な可視化です。
なぜ widyr を使うのか
pairwise_count() は、あるグループの中で一緒に現れた項目ペアの回数を tidy data の形で返してくれます。テキスト分析とネットワーク可視化の橋渡しがしやすいのが利点です。
なぜ 10 行ごとの section を使うのか
1 行だけだと窓が狭すぎてペアが少なくなり、章全体だと広すぎて語が何でもつながります。最初の練習では、10 行や 20 行ごとの小さな窓に区切ると、ほどよい粒度で図が作れます。
このページで扱う流れ
austen_books()で公開テキストを取得するunnest_tokens()で 1 行 1 単語へ変換するanti_join(get_stopwords())で stopwords を外すpairwise_count(word, section)で共起ペアを数える- 上位ペアを
graph_from_data_frame()に渡し、ggraph()で可視化する
Interpretation checks
読むときの注意点
共起ネットワークは便利ですが、作り方の選択で結果がかなり変わります。とくに、どの窓で数えるか、どの語を残すかは、解釈に直結します。
窓の大きさで図が変わる
1 行単位と 20 行単位では、つながる語の数も強さも変わります。結果を示すときは、どの単位で共起を数えたかを書き添えます。
頻出語が中心に見えやすい
人物名や一般語は多くの語と結びつきやすく、ネットワークの中心に現れがちです。中心にいることと重要性そのものを同一視しすぎないようにします。
共起は意味関係の証明ではない
一緒に出ることは、同義・因果・感情的な結びつきを直接示すものではありません。文脈確認や章別比較と併用するのが安全です。
Data structure
データ構造
共起ネットワークでは、まず tidy text を作り、その後に「共起を数える単位」を列として追加します。このページでは 10 行ごとの section を使います。
単語テーブルのイメージ
| line | section | word |
|---|---|---|
| 101 | 10 | elizabeth |
| 101 | 10 | darcy |
| 102 | 10 | jane |
| 109 | 10 | bennet |
| 111 | 11 | lady |
同じ section に入った単語どうしが、共起候補として数えられます。
共起ペア表のイメージ
| item1 | item2 | n |
|---|---|---|
| elizabeth | darcy | 18 |
| elizabeth | jane | 15 |
| jane | bingley | 12 |
| lady | catherine | 11 |
| lydia | wickham | 10 |
この表の各行が、そのままネットワークのエッジとして使えます。
Code
Rコード
下のコードをそのまま使えば、公開テキストの取得から共起ネットワーク図の保存まで一通り試せます。最初はしきい値 n >= 8 をそのまま使い、図がどう変わるかを確認してください。
install.packages(c(
"tidyverse",
"tidytext",
"janeaustenr",
"widyr",
"igraph",
"ggraph"
))
library(tidyverse)
library(tidytext)
library(janeaustenr)
library(widyr)
library(igraph)
library(ggraph)
books <- austen_books() %>%
filter(book == "Pride & Prejudice") %>%
mutate(line = row_number(),
section = line %/% 10)
tidy_words <- books %>%
unnest_tokens(word, text) %>%
anti_join(get_stopwords(), by = "word") %>%
filter(str_detect(word, "^[a-z']+$"))
pairs <- tidy_words %>%
pairwise_count(word, section, sort = TRUE, upper = FALSE)
pairs %>%
slice_max(n, n = 15)top_pairs <- pairs %>%
filter(n >= 8) %>%
slice_max(n, n = 80)
g <- graph_from_data_frame(top_pairs, directed = FALSE)
set.seed(123)
p <- ggraph(g, layout = "fr") +
geom_edge_link(aes(width = n), alpha = 0.18, show.legend = FALSE) +
geom_node_point(color = "#2f67d8", size = 4.5) +
geom_node_text(aes(label = name), repel = TRUE, size = 3) +
theme_graph()
print(p)
ggsave("cooccurrence_network_pp.png", plot = p, width = 8, height = 6)コードの最小ポイント
section = line %/% 10は、10 行ごとの窓を作る簡単な方法です。pairwise_count(word, section)は、同じ section に現れた単語ペアの回数を数えます。graph_from_data_frame()は、item1 / item2 / n の表をネットワークとして扱う入口です。- しきい値を上げると図はすっきりし、下げると密になります。まずは
n >= 8付近から試すのが扱いやすいです。
Output
出力の読み方
最初に見るべき出力は、上位の共起ペア表です。どの語どうしが一緒に現れやすいかを表で確認してから図を見ると、ネットワーク図を言葉にしやすくなります。
上位ペアの例
| 順位 | pair | n | 読み方 |
|---|---|---|---|
| 1 | elizabeth – darcy | 18 | 主要人物どうしの結びつきが強い |
| 2 | elizabeth – jane | 15 | 家族・対話の文脈で頻繁に現れる |
| 3 | jane – bingley | 12 | 人物関係の軸をなす組み合わせ |
| 4 | lady – catherine | 11 | 称号と固有名詞がセットで出やすい |
| 5 | lydia – wickham | 10 | 局所的だが特徴的なペア |
実際の順位は stopwords や窓幅、しきい値で少し変わります。
まず確認するポイント
- 主要人物名のペアが上位に来ているか
- 称号や一般語が中心に出すぎていないか
- 局所的に強いペア(例:lydia–wickham)が見えるか
表と図の役割分担
表は「どのペアが強いか」を正確に確認するため、図は「どの語群がまとまって見えるか」を探索的に眺めるために使います。両方をセットで置くと誤読しにくくなります。
Figure reading
共起ネットワーク図をどう読むか
共起ネットワーク図では、線の有無と強さ、ノードの位置、中心にまとまる語群を読みます。ただし、位置そのものはレイアウト結果なので、厳密な座標解釈はしません。
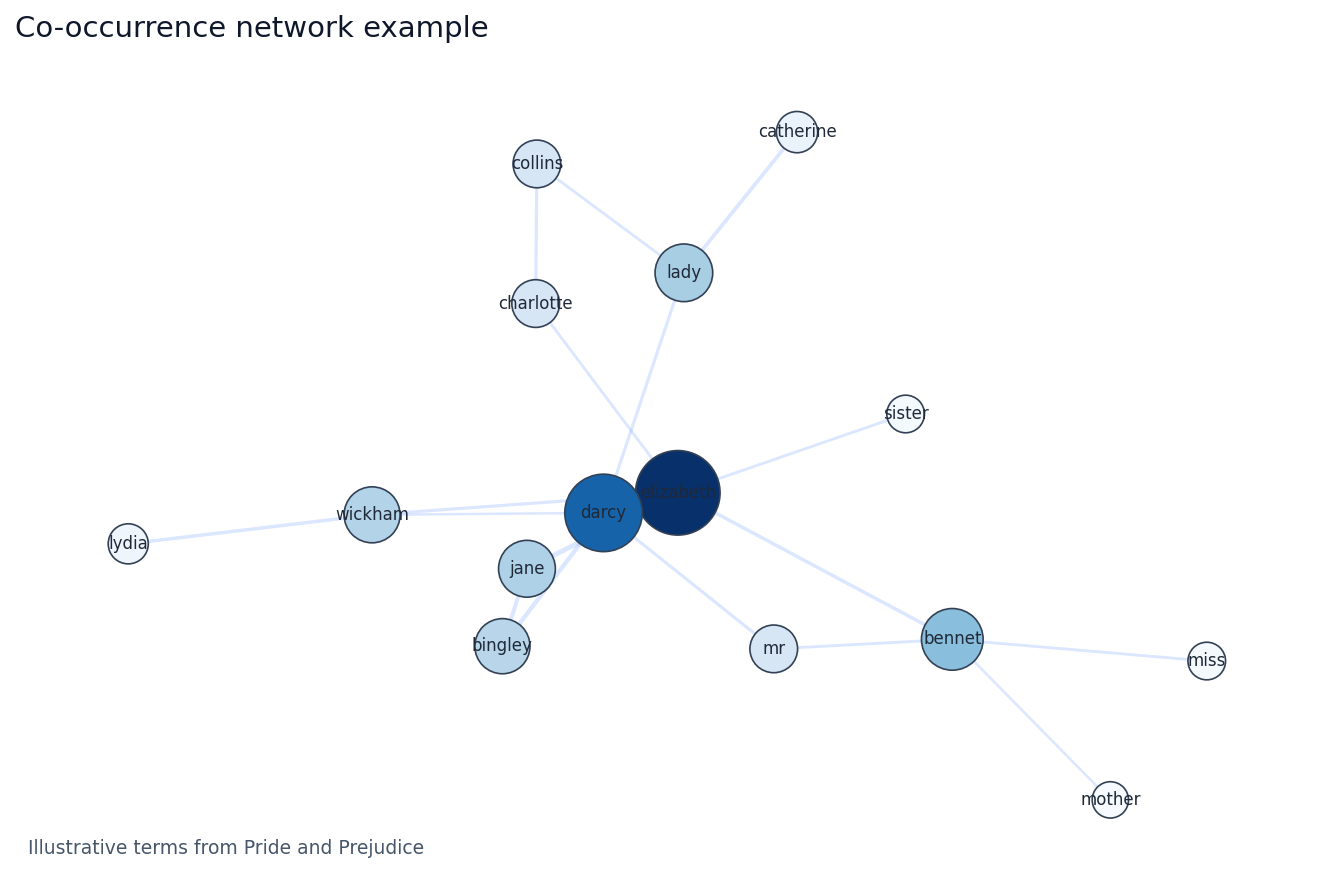
図1 Pride & Prejudice における共起ネットワーク図(例)
Figure 1. Example co-occurrence network of words in Pride & Prejudice.
中心付近の語を見る
elizabeth や darcy のように多くの語と結びつく単語は、ネットワークの中心に現れやすくなります。
局所クラスターを見る
lady – catherine、lydia – wickham のような組み合わせは、局所的にまとまりとして見えやすく、人物関係の手がかりになります。
線の太さを見る
エッジに重みを載せると、どのペアがより頻繁に共起したかを視覚的に表せます。
図だけで言い切らない
図の見た目は入口です。強い解釈をするときは、上位ペア表や実際の本文を確認して裏取りします。
Report writing
レポート用の結果記述例
共起ネットワークの記述では、対象作品、前処理、共起の単位、上位で目立ったペアや語群を書くと、読み手が手法と結果を追いやすくなります。
日本語の書き方例
Jane Austen の Pride & Prejudice を対象に、テキストを単語へ分割し、英語のストップワードを除いたうえで、10 行ごとの区間を単位として共起語ペアを集計した。共起ネットワーク図では、Elizabeth と Darcy が中心的な位置を占め、Jane や Bingley などの人物名が近接して配置された。また、Lady と Catherine、Lydia と Wickham といった局所的なペアも確認された。図1に共起ネットワークの例を示す。
図1 Pride & Prejudice における共起ネットワーク図(例)
English writing example
Using Pride & Prejudice, the text was tokenized into words, English stopwords were removed, and co-occurring word pairs were counted within 10-line sections. The resulting co-occurrence network showed Elizabeth and Darcy in central positions, with nearby clusters involving names such as Jane and Bingley. Localized pairs such as Lady–Catherine and Lydia–Wickham were also visible. Figure 1 presents an example co-occurrence network.
Figure 1. Example co-occurrence network of words in Pride & Prejudice.
Common mistakes
よくあるミス
窓が狭すぎて線がほとんど出ない
1 行単位や 1 文単位にすると、作品によってはペアが少なすぎます。10 行や段落単位のような少し広い窓も試してみます。
一般語や称号が中心を占める
miss, mr, lady のような語は頻出しやすいので、必要に応じて追加 stopwords を作ると読みやすくなります。
しきい値を下げすぎて毛玉になる
共起回数の閾値が低すぎると、線が多すぎて図が読めなくなります。まずは上位 50〜80 辺くらいを目安に調整します。
共起を意味関係や因果と取り違える
一緒に出ることは、関係の存在を示唆するにとどまります。語の意味や物語上の役割は本文に戻って確認します。
FAQ
FAQ
Q. bigram と共起ネットワークは何が違いますか?
A. bigram は隣り合う 2 語を直接数える方法です。共起ネットワークは、同じ窓の中に現れた語同士を広めに数えるので、少し離れた語の結びつきも拾えます。
Q. 日本語テキストでも同じようにできますか?
A. 考え方は同じです。ただし、日本語では単語境界を切るための形態素解析やトークナイザ設定が必要になります。
Q. どの窓幅を選べばよいですか?
A. 正解は1つではありません。文章の長さや研究質問に応じて複数の窓幅を試し、図の読めやすさと解釈可能性のバランスを確認します。
代替手法
代替手法・次の一歩
共起ネットワークは、頻度表と意味理解のあいだをつなぐ便利な入口です。研究質問によっては、次のような発展先の方が合うこともあります。
単語頻度に戻る
まずは上位語を安定して読みたい場合は、単語頻度ページ に戻って count() と棒グラフを固める方が理解しやすいです。
bigram / n-gram
隣り合う語の結びつきを見たい場合は、共起窓ではなく bigram の頻度表を作ると、語句レベルのパターンを読み取りやすくなります。
pairwise_cor()
単語ペアの単純な回数ではなく、共起傾向の強さを相関として見たい場合は pairwise_cor() に進むと、頻出語の影響を少し調整しながら眺められます。
人物ネットワークへ進む
単語ではなく登場人物の関係そのものを扱いたい場合は、ネットワーク分析の入門 で中心性やレイアウトの基本を確認するとつながります。
参考資料
参考資料
このページでは、実装に直結する一次資料寄りのリンクを中心に並べています。まずは tidytext と widyr、その後に igraph / ggraph を見る流れがおすすめです。
テキスト整形と共起集計
共起ネットワークの前半は、tidy text の作成と pairwise_count() の理解が鍵になります。
ネットワーク化と可視化
共起ペア表を graph object へ変換して図にする流れは、他のネットワーク分析ページにも応用できます。
発展先
大量テキストや DFM ベースの処理へ進みたい場合は quanteda が有力です。
運営と利用上の注意
このページの位置づけ
本サイトのトピックページは、Rによるデータ分析の学習支援とレポート作成の補助を目的としたオリジナル解説です。サンプルデータとコードは再現練習用に作成しているため、実データを扱う際には研究計画・前提条件・欠測・外れ値・尺度水準をあらためて確認してください。
編集方針
ページ本文は、標準的な統計手法、Rの公式ドキュメント、一次資料に近い参考文献を優先して整理しています。更新や訂正の方針は編集方針ページで公開しています。