Topic 22
テキスト分析の入門:Jane Austen 作品 × tidytext × 単語頻度棒グラフ
Beginner text analysis in R with Jane Austen books and tidytext
R でテキスト分析を最短距離で体験したい人向けの入門ページです。追加データを用意しなくても、Jane Austen の公開テキストを使って、取得 → トークン化 → ストップワード除去 → 単語頻度集計 → 棒グラフ作成まで一気通貫で試せます。
テキスト分析では、まず文章を単語や文の単位に分けます。このページでは最も基本的な単位である単語(unigram)を扱い、どの語がよく出るかを確認します。
扱うのは tidytext の入門でもよく使われる Jane Austen 作品です。外部ファイルなしで再現できるので、RStudio の環境確認とテキスト分析の最初の練習を同時に進められます。
最初のゴールは『高度な自然言語処理をすること』ではなく、『テキストを tidy data に直して、頻度表と棒グラフを自分で作れるようになること』です。
このページのゴール
- 文章データを単語に分けるトークン化の意味を理解する
- austen_books() で公開テキストを取得し、作品単位の集計を確認する
- unnest_tokens() と anti_join(get_stopwords()) で tidy text を作れるようになる
- Pride & Prejudice の上位語を count() で集計し、棒グラフとして可視化できる
- 単語頻度の結果を、課題やレポートでどう文章化するかの型をつかむ
Learn the idea
まず押さえるポイント
テキスト分析は、文章をそのまま眺めるのではなく、単語に分ける、不要語を除く、頻度を数えるという形に整えて、内容の傾向を要約していく分析です。最初は「トークン化」「ストップワード」「頻度表」の3語が分かれば十分です。
文章を単語や文に分ける操作です。このページでは単語単位の unigram を扱います。
the, and, of のように、頻出するが内容理解には寄与しにくい語です。最初に除くことが多いです。
どの語がよく出るかを見る最も基本的な集計です。作品の中心人物や話題が見えやすくなります。
上位語の頻度を棒グラフにすると、表だけより全体像を素早く読み取りやすくなります。
Basics
このページの分析の考え方
今回のゴールは、高度な自然言語処理よりも「R でテキストを tidy data として扱えるようになること」です。そのため、まずは janeaustenr の公開作品を読み込み、unnest_tokens() で単語に分け、anti_join(get_stopwords()) で不要語を外し、count() で頻度を数えます。
なぜ Jane Austen 作品なのか
公開データで追加ファイルが不要なうえ、作品名ごとにまとまっていて、トークン化や頻度集計の練習に向いています。R の環境テストにも使いやすいのが利点です。
なぜ単語頻度から始めるのか
単語頻度は、テキスト分析の最も基本的な出力です。ここが分かると、感情分析、共起、トピックモデルなどの発展テーマにも進みやすくなります。
このページで扱う分析の流れ
austen_books()で公開テキストを取得するcount(book)で作品ごとの行数をざっと確認するunnest_tokens(word, text)で 1 行 1 単語へ展開するanti_join(get_stopwords(), by = "word")で不要語を除くcount(word, sort = TRUE)とgeom_col()で上位語を図にする
Interpretation checks
読むときの注意点
単語頻度は便利ですが、語が多いことと重要であることは同じではありません。初学者は、ストップワード処理と文脈の欠落という2点を意識して読むだけでも、解釈がかなり安定します。
固有名詞が上位に来やすい
小説では登場人物名が多く出るため、上位語が人物名で埋まることがあります。これは異常ではなく、作品構造の一部としてまず受け止めます。
単語頻度だけでは文脈が落ちる
単語を1つずつ数えると、誰が誰に何を言ったかのような順序や文脈は失われます。解釈を深めるには共起や章別比較が有効です。
ストップワードの定義で結果が変わる
どの語を不要語として除くかで、上位語リストは少し変わります。レポートでは、英語 stopwords を除いたことを一言書いておくと親切です。
日本語テキストは別の下準備が必要
このページは英語テキストの最小例です。日本語では形態素解析や辞書設定が必要になるため、同じコードをそのまま日本語へ当てることはできません。
Data structure
データの形をつかむ
テキスト分析の最初の壁は、元の文章データと、分析に使う tidy text の形が違うことです。ここでは austen_books() の出力と、unnest_tokens() 後の出力を見比べて、何が変わるのかを押さえます。
元データ:1行が1行分の文字列
| book | text |
|---|---|
| Sense & Sensibility | SENSE AND SENSIBILITY |
| Sense & Sensibility | by Jane Austen |
| Pride & Prejudice | PRIDE AND PREJUDICE |
| Pride & Prejudice | It is a truth universally acknowledged... |
| Pride & Prejudice | However little known the feelings... |
まずは「本ごとに、行単位で text が並んでいる」データとして入ってきます。
整形後:1行が1単語の tidy text
| book | word |
|---|---|
| Pride & Prejudice | truth |
| Pride & Prejudice | universally |
| Pride & Prejudice | acknowledged |
| Pride & Prejudice | however |
| Pride & Prejudice | feelings |
unnest_tokens() 後は 1 行 1 単語になります。この形にしてから count() が使いやすくなります。
Code
Rコード
下のコードはそのままコピーボタンで持っていき、RStudio へ貼れば動く形にしてあります。まずは 1 本目を実行して、作品一覧と pp_top の表が出るところを確認してください。
install.packages(c("tidyverse", "tidytext", "janeaustenr", "ggplot2"))
library(tidyverse)
library(tidytext)
library(janeaustenr)
library(ggplot2)
# 1) 公開テキストを取得
books <- austen_books()
books %>% count(book)
# 2) トークン化 → ストップワード除去 → 単語頻度(Pride & Prejudice)
tidy_books <- books %>%
unnest_tokens(word, text) %>%
anti_join(get_stopwords(), by = "word")
pp_top <- tidy_books %>%
filter(book == "Pride & Prejudice") %>%
count(word, sort = TRUE) %>%
slice_max(n, n = 15, with_ties = FALSE)
print(pp_top)pp_plot <- pp_top %>%
ggplot(aes(reorder(word, n), n)) +
geom_col(fill = "#2b8cbe") +
coord_flip() +
labs(
title = "Top words in Pride & Prejudice",
x = NULL,
y = "count"
) +
theme_minimal(base_size = 13)
print(pp_plot)
ggsave("pp_top_words.png", plot = pp_plot, width = 6, height = 4)コードの最小ポイント
austen_books()は追加ファイルなしで公開テキストを返してくれます。unnest_tokens()で 1 行 1 単語の tidy 形式へ変換します。anti_join(get_stopwords(), by = "word")を入れると、英語の stopwords を外せます。coord_flip()を使うと、長い単語ラベルでも読みやすい棒グラフになります。
Output reading
最初に読むべき出力
テキスト分析の最初の出力は、検定表ではなく頻度表です。まずは作品ごとの件数と、対象作品の上位語テーブルを見て、「何を数えているか」が腑に落ちるかを確認してください。
作品一覧の確認
books %>% count(book) を実行すると、どの作品が何行で収録されているかをざっと確認できます。ここで Pride & Prejudice という作品名が存在することを先に見ておくと、あとで filter(book == "...") を安心して使えます。
- 作品名のスペルを確認する
- 本ごとの規模感が大きく違わないかを見る
- 空行やタイトル行が混ざることを念頭に置く
上位語テーブルの例
| word | n |
|---|---|
| elizabeth | 640 |
| darcy | 420 |
| bennet | 320 |
| jane | 295 |
| bingley | 270 |
| miss | 245 |
| lady | 230 |
| sister | 215 |
上の値は出力の読み方を示す例です。実際の順位や件数は stopwords の定義や ties の扱いで少し変わることがあります。
Figure reading
単語頻度棒グラフをどう読むか
この図では、棒の長さが単語の出現頻度を表しています。まずは人物名や役割語が上位に来ているかを見て、次に「作品の内容理解にどうつなげるか」を考えると読みやすくなります。
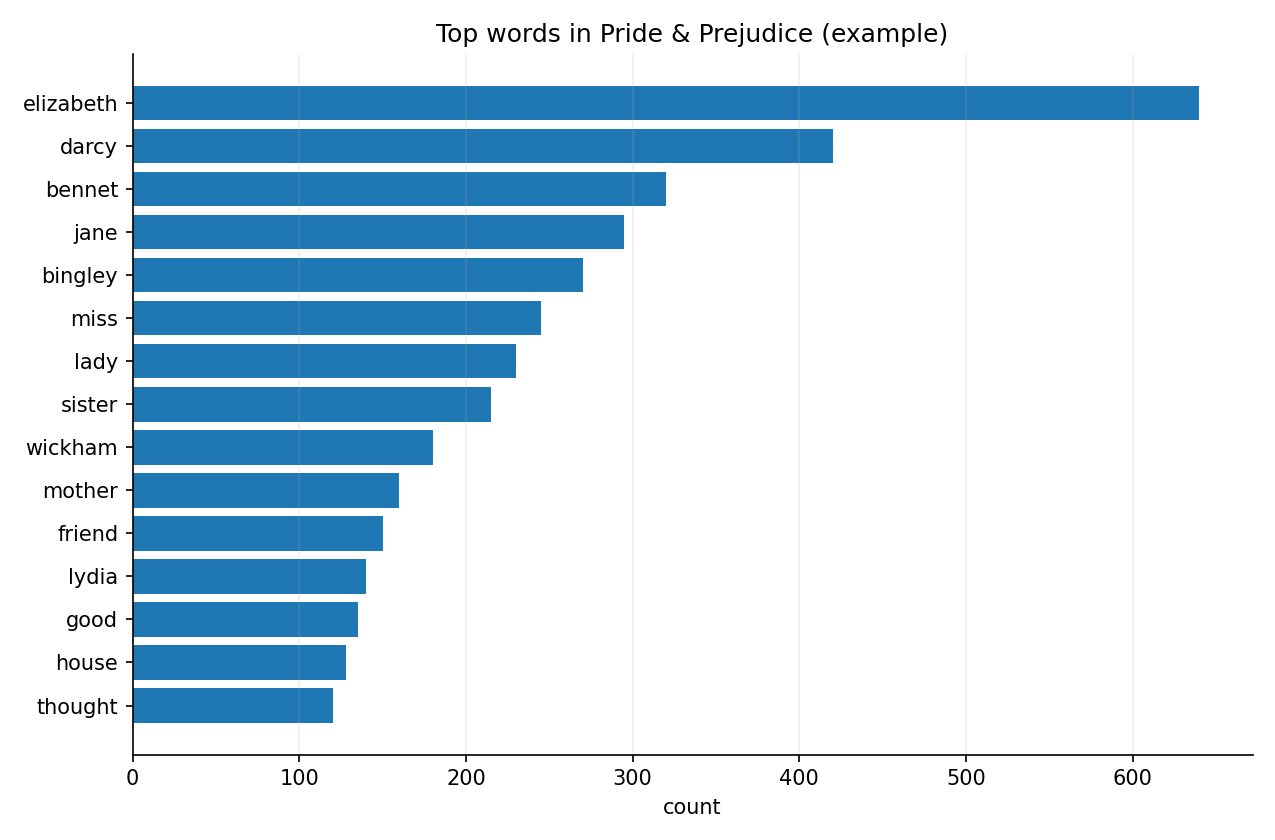
図1 Pride & Prejudice における上位語の棒グラフ(例)
Figure 1. Example bar chart of the most frequent words in Pride & Prejudice.
人物名が上位に出るか
elizabeth や darcy のような固有名詞が上位に並ぶと、作品内で人物が中心的な役割を持っていることが視覚的に分かります。
役割語・関係語にも注目
miss, lady, sister などは、人物名とは別に社会的な立場や関係性を反映する語として読めます。
差の大きさを読む
1位と2位の差、上位群と下位群の差を見ると、特定の語がどれくらい強く目立っているかを把握しやすくなります。
頻度は入口にすぎない
頻度だけでは語の使われ方までは分かりません。次の一歩として、章別比較や共起、感情分析へ進むと理解が深まります。
Report writing
レポート用の結果記述例
テキスト分析の最初の記述では、何を対象に、どの前処理を行い、何を数えたかを簡潔に書くのが基本です。頻度の結果だけで強い文学解釈を行うのではなく、探索的要約であることも添えると丁寧です。
日本語の書き方例
Pride & Prejudice を対象に、テキストを単語単位へトークン化し、英語のストップワードを除いた上で単語頻度を集計した。その結果、上位語には Elizabeth、Darcy、Bennet などの人物名が多く含まれ、作品内容が主要人物を中心に展開していることが示唆された。図1に上位15語の頻度棒グラフを示す。なお、単語頻度は文脈を落とした探索的指標であるため、解釈には章別比較や共起分析などを併用することが望ましい。
図1 Pride & Prejudice における上位語の棒グラフ(例)
English writing example
Using Pride & Prejudice, the text was tokenized into individual words, English stopwords were removed, and word frequencies were summarized. The most frequent terms included character names such as Elizabeth, Darcy, and Bennet, suggesting that the narrative is strongly centered on its main characters. Figure 1 shows an example bar chart of the top 15 words. Because word-frequency summaries remove local context, they should be interpreted as an exploratory overview rather than a complete reading of the text.
Figure 1. Example bar chart of the most frequent words in Pride & Prejudice.
Common mistakes
よくあるミス
stopwords を外さずに解釈してしまう
the, and, of などが上位を占めると、内容理解につながりにくい表になります。まず stopwords を除いた版を作ってから読み始めます。
作品名のフィルタ条件を誤る
filter(book == "Pride & Prejudice") のスペルがずれると空データになります。先に count(book) で確認するのが安全です。
頻度を「重要性」と言い切る
出現頻度が高いことは注目点の1つですが、重要性やテーマ性そのものとは限りません。頻度は入口として扱います。
日本語へそのまま流用する
この最小例は英語テキスト用です。日本語では単語境界の扱いが異なるため、追加の前処理やトークナイザ設定が必要です。
FAQ
FAQ
Q. 日本語テキストでも同じようにできますか?
A. 発想は同じですが、単語の切り方が異なるため、英語の最小コードをそのまま使うことはできません。まずは英語例で流れをつかみ、その後に日本語向けのトークン化手順へ進むのがおすすめです。
Q. 頻度以外には何をすると発展になりますか?
A. 感情分析、bigram / 共起、章別比較、トピックモデルが代表的です。頻度表の次の一歩としては、2語の組み合わせを見る bigram が理解しやすいです。
Q. tidytext と quanteda はどう使い分けますか?
A. 初学者が「整然データとして扱いたい」ときは tidytext が入りやすく、大量テキストや DFM を素早く作りたいときは quanteda が便利です。両者は対立ではなく補完関係です。
代替手法
代替手法・次の一歩
単語頻度を入口にしたあと、研究質問に応じて次の手法へ進むと、テキストの読み取りが深まります。ここでは、初学者がつまずきにくい順に発展先を並べています。
感情分析
positive / negative の辞書を使って、章や作品ごとに感情語の偏りを見たいときの次の一歩です。tidytext の get_sentiments() から入りやすいです。
bigram / 共起
単語どうしの結びつきや文脈を見たいときは、2語の組み合わせや共起関係を見ると、頻度表より一段深い理解につながります。実際に図として試すなら 共起ネットワークの発展ページ が次の入口です。
quanteda に進む
大量テキストを高速に前処理したい、DFM を作って機械学習や比較分析へつなげたい、という場合は quanteda 系へ進むと見通しがよくなります。
ネットワーク分析とつなげる
単語共起ネットワークや人物関係ネットワークへ広げたいときは、ネットワーク分析ページ を次の入口にすると流れがつながります。
参考資料
参考資料
このページは、実装の入口を優先して、公式ドキュメントと一次資料に近いページを中心に並べています。まずは tidytext と janeaustenr、その後に quanteda や stm へ進むと流れがつながります。
最初に押さえる資料
まずは tidytext の入門記事で unnest_tokens() と Jane Austen 作品の扱いを確認すると、このページのコードが読みやすくなります。
データ操作と可視化
count()、filter()、slice_max() と棒グラフの組み合わせは、テキスト分析に限らず多くの集計ページで再利用できます。
高速前処理・日本語への発展
日本語や大量テキストを扱う場合は、tokens → dfm の流れを持つ quanteda も有力な選択肢になります。
トピックモデル・次の一歩
頻度や共起のさらに先で、文書ごとの潜在トピックを見たいときはトピックモデルが発展先になります。
運営と利用上の注意
このページの位置づけ
本サイトのトピックページは、Rによるデータ分析の学習支援とレポート作成の補助を目的としたオリジナル解説です。サンプルデータとコードは再現練習用に作成しているため、実データを扱う際には研究計画・前提条件・欠測・外れ値・尺度水準をあらためて確認してください。
編集方針
ページ本文は、標準的な統計手法、Rの公式ドキュメント、一次資料に近い参考文献を優先して整理しています。更新や訂正の方針は編集方針ページで公開しています。